In this repository, I am going to work on some data stes, which are available free on internet (their links will be attached) with time series features.
In this attempt I investigated the effect of changing hyperparameters such as numbers of units, drop out and learning rate value, optimizer, time steps and also adding some dense layer instead of one layer in out put to acheive a better performance. The investigations were done on a public dataset, named Jena Climate Dataset (it is accessable via https://www.kaggle.com/datasets/mnassrib/jena-climate). It is a timeseries dataset recorded at the Weather Station of the Max Planck Institute in Jena, Germany. Also, the script of this part uploaded as 'Temperature Prediction'.
As the results show As the results show decreasing numbers of units can cause the reduction rate of loss, mae, validation loss and validation mae to reduce.
LSTM32:

LSTM16:

LSTM2:

But increasing numbers of units can be an effective way if overfit phenomenon not to be happened. Hence, drop out layers and also recurrent drop out in LSTM layers should be added to prevent overfit along with improve the reduction rate of loss, mae, mse, validation loss and validation mae.
LSTM64:

LSTM64 and drop out 0.75 and recurrent drop pout 0.5:

LSTM64 and drop out 0.75 and recurrent drop pout 0.75:
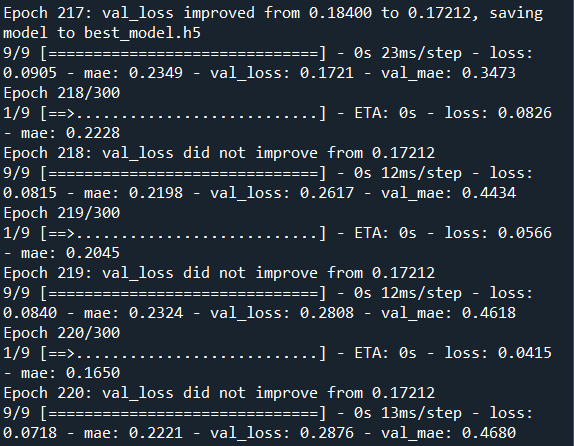
Based on our investigation considering 0.001 as learning rate value for rmsprop act better than other learning rate values.
LSTM32 and default learning rate value:

LSTM32 and learning rate 0.1:

LSTM32 and learning rate 0.01:

LSTM32 and learning rate 0.001:

LSTM32 and learning rate 0.0001:

LSTM32 and learning rate 0.00001:

And it is worth mentioning the results depict even though rmsprop optimizer had better performance on training data, validation loss and validation mae reduction was better when adam were implemented. It can be concluded, using adam can reduce the chance of overfitting.
LSTM32 and rmsprop:

LSTM32 and adam:

As the results show, adding some dense layers (respectively 128,64 and 32) can improve the performance of our architecture.
LSTM32 and a dense (one unit) output layer:

LSTM32 and adding three extra dense (respectively 128, 64 and 32) layers:

Comparison among different sequence lengths illustrate that longer sequence length not only increase the process time, but also raise the loss and mae on both training and validation set. In fact, considering longer sequence length required changing other hyper parameters such as adding extra layers to our architecture, otherwise it may reduce its performance.
LSTM32 and sequence length 120:

LSTM32 and sequence length 80:

LSTM32 and sequence length 160:

In this section I used a dense layer instead of LSTM to predict last section time series. The results demonstrated a huge difference. This section code uploaded as 'Dense Instead of LSTM'.
LSTM32:

Dense instead of LSTM32:

In this part, I tried to make a comparison among performance of LSTM, GRU and SimpleRNN via constracting a sine wave and test these algorithms performance in prediction of the constructed wave. The results show the better performance of GRU. This issue was according our expectation but GRU better convergence and lower loss, mae, validation loss and validation mae in comparison with LSTM was a bit strange. I think this is because this series is not complicated enough and therefore it is no need to utilize LSTM. The script of this section uploaded as 'Sin Project'.
GRU:

LSTM:

SimpleRNN:

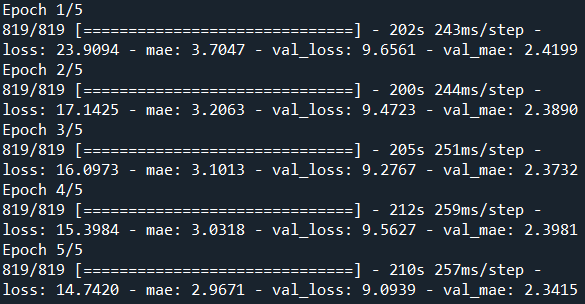
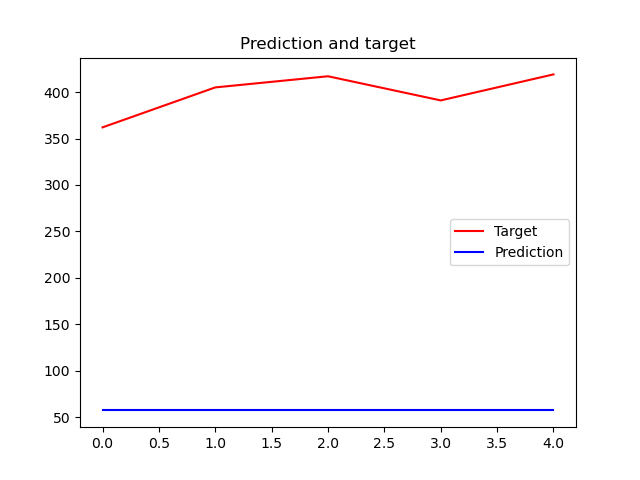
This is a time series anticipation project. It seems there is not fundamental differences among this dataset and the previous one but implementing last scrip (with little changes) did not show as good result as last part. In fact, even though by increasing epochs the loss, mae, validation loss and validation mae reduced, the algorithm could not convergent within 300 epochs. This issue is because dataset values were huge. Hence, I decided to normalize data and you can see the effect of normalization on convergence below. This part code uploaded as 'Number of Passengers Project'.
LSTM epochs without normalizing:

LSTM training and validation loss without normalizing:

LSTM training and validation mae without normalizing:

LSTM prediction without normalizing:
LSTM epochs with normalizing:

LSTM training and validation loss with normalizing:

LSTM training and validation mae with normalizing:

LSTM prediction with normalizing:

I also tried to improve the performance of my network via adding drop out layer and recurrent drop out in LSTM layer, but actually this issue did not improve the performance of our network at all.
Previous architecture with adding a drop out (0.5) layer:




Previous architecture with adding recurrent drop out (0.5) in LSTM layer: