This repoistory contains research about Particle Swarm Optimization (PSO) and it's implementation to optimize Artificial Neural Network (ANN)
- The Persentation of PSO
- The Paper of PSO
- Code for PSO is from: kuhess/pso-ann
- Used MNIST Dataset for Training ANN using PSO which you can download it from
-
Motivation
- Gradient Descent requires differentiable activation function to calculate derivates making it slower than feedforward
- To speed up backprop lot of memory is required to store activations
- Backpropagation is strongly dependent on weights and biases initialization. A bad choice can lead to stagnation at local minima and so a suboptimal solution is found.
- Backpropagation cannot make full use of parallelization due to its sequential nature
-
Advantages of PSO
- PSO does not require a differentiable or continous function
- PSO leads to better convergence and is less likely to get stuck at local minima
- Faster on GPU
- Windows 10
- AMD GPU radeon 530
- Python 3.9
- matplotlib 3.3
- numpy 1.19.5
- scikit-learn 0.24
- scipy 1.6.0
$ git clone https://github.com/aboelkassem/PSO.git
$ cd PSO
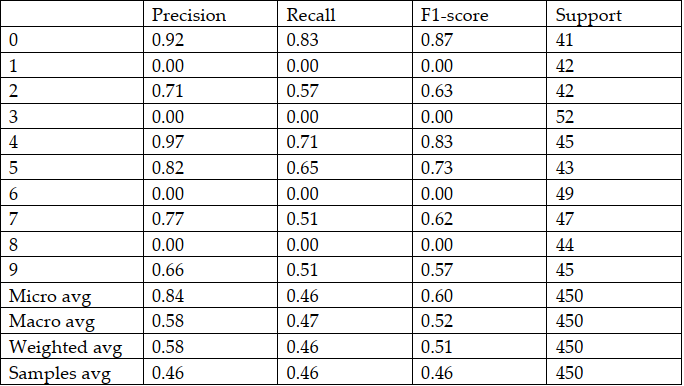
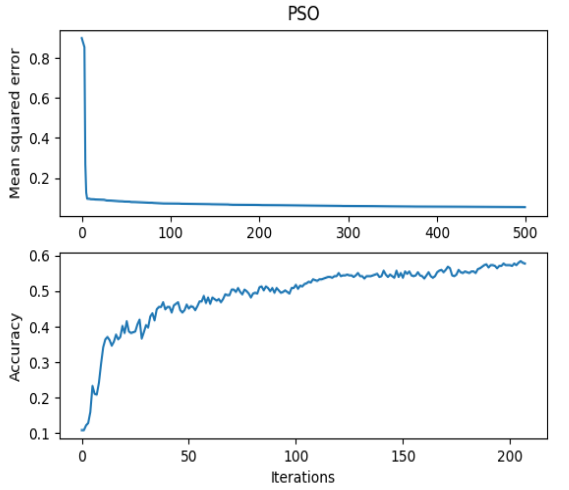
$ python example_mnist.pythe following diagram and reports shows the performance of testing data of the dataset including 10 classes (digits classes)