Fix pruning bounds #1009
Fix pruning bounds #1009
Conversation
| # We won't do any assertion in this test, just printing out the losses, | ||
| # because we can not 100% sure that the new method is better than the old | ||
| # one all the time, both of them are local optimal bounds. | ||
| def test_prune_ranges(self): |
There was a problem hiding this comment.
I tested the two pruning bounds here, first, I generated a mask according to the ranges, and filled the logits with 0.0 at the positions outof ranges. then, I computed the loss of the modifed logits. If the new pruning bounds is better than the old one, the loss should be smaller. From my experiments (both on real data and random generated data), most of the time, the loss of the logit pruned with new bounds is smaller than the one pruned with old bounds. But it can not 100% gurantee it. If I did something wrong, please LMK @danpovey, thanks!
| if s_range > S: | ||
| s_range = S | ||
| s_range = S + 1 |
There was a problem hiding this comment.
The buggy code that raises nan or inf loss is here. It only occurs when S==1 and modified==False, because when modified==False the transitions can only go up and right, so s_range MUST be equal to or greater than 2, or no path can survive pruning.
|
I tested the new bounds and old bounds on real data (librispech 100h), in the following figure, pink one is the curve of loss pruned by old bounds, blun one is the curve of loss pruned by new bounds (Note, I used the trivial joiner to calculate the losses). You can see in the figure, only in the early batches, the loss of the new one is a little larger than the old one, after 3k iterations, the old one is identical to the new one. I also compared the pruning bounds, in the early 3k iterations,
|

|
It seems that the old / new bounds are almost identical, I will use the new bounds to reproduce one of our recipes. |
|
I tried this new pruning bounds on our two baseline recipes, here are the results: From the following results, training with new pruning bounds makes some improvements on pruned_transducer_stateless4 recipe, especially on test-other. While on pruned_transducer_stateless5 (exp-B, 88MB parameters), I got slightly worse results. pruned transducer stateless4
pruned transducer stateless5 exp-B
|



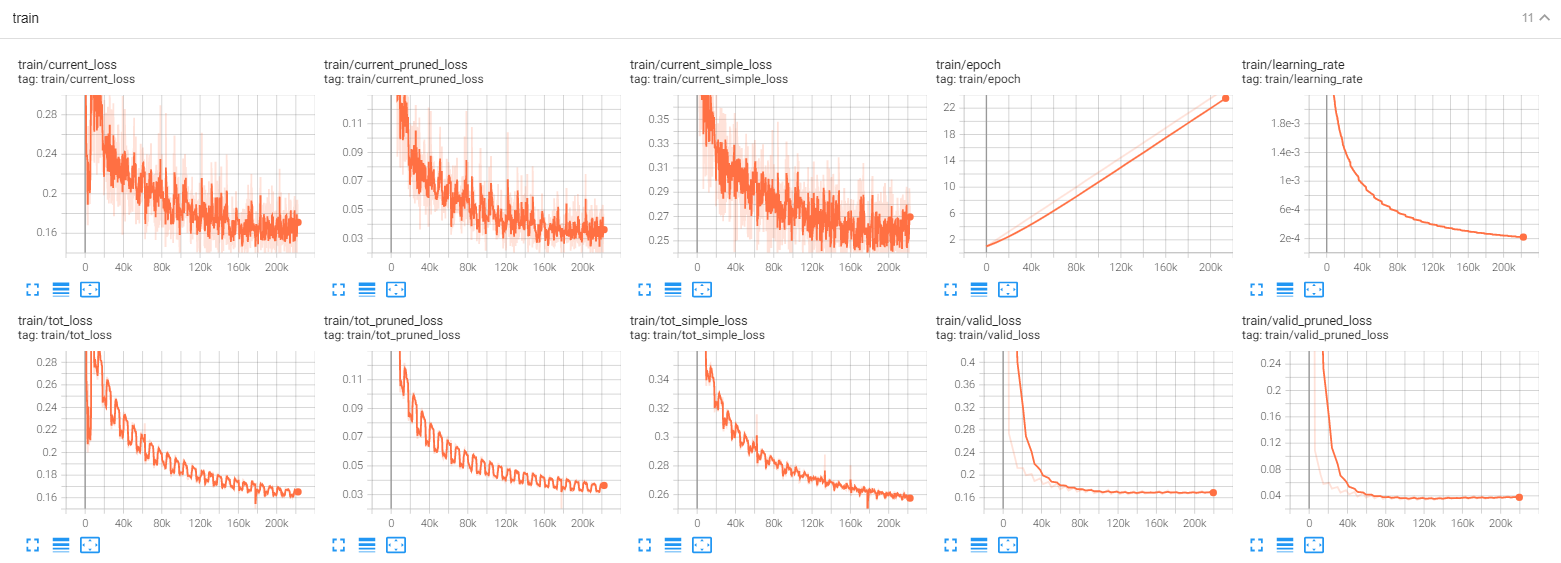
|
I conducted two experiments to compare the pruned loss value of old bounds and new bounds. It seems that whether we use "old bounds" or "new bounds" in train, the loss values of "new bounds" are always larger than that of "old bounds" at the early iterations. BTW from the picture, we can see "new bounds" helps to converge faster, the only difference of these two experiments are the bounds used for pruning. training with new bouldsThe blue curve is for new bounds code to generate tensorboard above ranges = k2.get_rnnt_prune_ranges(
px_grad=px_grad,
py_grad=py_grad,
boundary=boundary,
s_range=prune_range,
)
# this loss will be used to train the model
pruned_loss = k2.rnnt_loss_pruned(
logits=logits.float(), # this logits is from joiner output.
symbols=y_padded,
ranges=ranges,
termination_symbol=blank_id,
boundary=boundary,
reduction="sum",
)
new_am_pruned, new_lm_pruned = k2.do_rnnt_pruning(am=am, lm=lm, ranges=ranges)
new_logits = new_am_pruned + new_lm_pruned
# this loss is used to draw the blue curve
new_pruned_loss = k2.rnnt_loss_pruned(
logits = new_logits.float(),
symbols=y_padded,
ranges=ranges,
termination_symbol=blank_id,
boundary=boundary,
reduction="sum",
)
old_ranges = k2.get_rnnt_prune_ranges_deprecated(
px_grad=px_grad,
py_grad=py_grad,
boundary=boundary,
s_range=prune_range,
)
old_am_pruned, old_lm_pruned = k2.do_rnnt_pruning(am=am, lm=lm, ranges=old_ranges)
old_logits = old_am_pruned + old_lm_pruned
# this loss is used to draw the pink curve
old_pruned_loss = k2.rnnt_loss_pruned(
logits = old_logits.float(),
symbols=y_padded,
ranges=old_ranges,
termination_symbol=blank_id,
boundary=boundary,
reduction="sum",
)
return (simple_loss, pruned_loss, new_pruned_loss, old_pruned_loss)training with old bouldsThe blue curve is for new bounds |

| s_range >= 2 | ||
| ), "Pruning range for standard RNN-T should be equal to or greater than 2, or no valid paths could survive pruning." | ||
|
|
||
| blk_grad = torch.as_strided( |
There was a problem hiding this comment.
Here, I think it would be better not to assume that py is contiguous, in place of S1 you should probably
be using py_grad.stride(2), and so on, and the S1 * T should be py_grad.stride(0) or possibly a variable called B_stride, e.g. (B_stride, S_stride, T_stride) = py_grad.stride()
k2/python/k2/rnnt_loss.py
Outdated
|
|
||
| # (B, T) | ||
| s_begin = torch.argmax(final_grad, axis=1) | ||
| s_begin = s_begin[:, :T] |
There was a problem hiding this comment.
this statement may be redundant?
| # padding value which is `len(symbols) - s_range + 1`. | ||
| # This is to guarantee that we reach the last symbol at last frame of real | ||
| # data. | ||
| mask = torch.arange(0, T, device=px_grad.device).reshape(1, T).expand(B, T) |
There was a problem hiding this comment.
can we comment to say what mask will be, e.g. its shape and when it is true?
|
After fixing those small issues and making sure the tests run, I incline towards merging this. |
Ok, will fix the issues and check the code again. Thanks! |
|
Thanks... looks OK to me. |
|
On real-world datasets the assert |
|
We should make sure there's a way for calling code to ignore this error. |
|
Yup (it's German if that matters). Doesn't happen that often honestly but just wanted to raise awareness. |
|
Ah, OK. For German it may be different than English (or might need larger BPE vocab). |
This PR fixes the issue of returning nan or inf loss (posted at k2-fsa/fast_rnnt#10).
It also updates the method to generate pruning bounds (i.e. the method we wrote in our pruned rnn-t paper). I did some experiments on April, but fogot to submit the code, sorry! About the new pruning bounds, I think we can not 100% gurantee it would be better than the old one, as both of them are local optimal bounds.