| Scope | Job | Linux | Windows | OSX |
|---|---|---|---|---|
| Unittest | CLI Unittest | |||
| GTK Unittest | ||||
| CLI Release | ||||
| GTK Release | ||||
| Package | CLI .zip | |||
| GTK .zip | ||||
| CLI .deb | N/A | N/A | ||
| GTK .deb | N/A | N/A | ||
| GTK .AppImage | N/A | N/A | ||
| Test | Install CLI .deb | N/A | N/A | |
| Install GTK .deb | N/A | N/A | ||
| Extract .AppImage | N/A | N/A | ||
| CLI Search Name Time | ||||
| CLI Search Content Time |
| Result | |
|---|---|
| Publish Beta | |
| Pipeline |





Get notified for latest releases
![]()
Search files without indexing, but clever crawling:
- At least 1 thread per mount point
- Use as much RAM as possible for caching stuff
- Try to avoid "black hole folders" using a regex based blocklist in which the crawler will never come out and never scan useful files (
node_modules,Windows,etc) - Intended for desktop users, no obscure Linux files and system files scans
- Use priority lists to first scan important folders.
- Betting on the future: slowly being optimized for SSDs/M.2 or fast RAID arrays
Install the provided .deb (sudo required) or just double click the AppImage (no sudo)
If your distro doesn't ask you to mark the AppImage as executable or nothing happens try:
chmod +x appimage_name_you_downloaded.AppImage./appimage_name_you_downloaded.AppImage
If you want a version that doesn't require sudo and can be configurable download the .zip files.
- Open = Left Double Click / Return / Enter / Space
Open containing folder = Contextual menu
Some dependencies don't build with GDC!!! Use DMD or LDC!!!
- If you omit
-b releasea slower debug version with infinite logs (NOT recommended) will be created - Note:
-b release-debugis somewhat in between a debug and a release version, it's compiled with fast code but it has debug checks enabled and some logs - Then build a configuration, check the possible ones inside
dub.json:dub build -b release -c CLIdub build -b release -c GTK- requires libgtk-3-dev
- etc...
- Output will be inside
./Build
- Install DMD
- on Linux download the .deb, don't install it from apt, be sure GDC doesn't get installed as backend compiler
- https://dlang.org/download.html#dmd
brew install gpgme
curl -fsS https://dlang.org/install.sh | bash -s dmd
# for the GTK version
brew install gtk+3
brew install glib
brew install gobject-introspection
source ~/dlang/dmd-$(dmd_version)/activate && dub build -c GTK -b release --arch=x86_64- Install DMD
- Install Visual Studio 2017
- Install VisualD
- dub generate visuald
- Open the project & Build Solution
Help! GDB crashes/halts!!!
D uses SIGUSR1 and SIGUSR2 to let the GC communicate with the threads.
Set GDB or your debugger to ignore them:
handle SIGUSR1 print nostop pass
handle SIGUSR2 print nostop pass
If you want to do this automagically add them to .gdbinit in /home/username/.gdbinit
Remember to pass the signals otherwise the threads will lock, ONLY ignore the stop in your debugger.
https://dlang.org/library/core/thread/thread_set_gc_signals.html
I was stressed on Linux because I couldn't find the files I needed, file searchers based on system indexing (updatedb) are prone to breaking and hard to configure for the average user, so did an all nighter and started this.
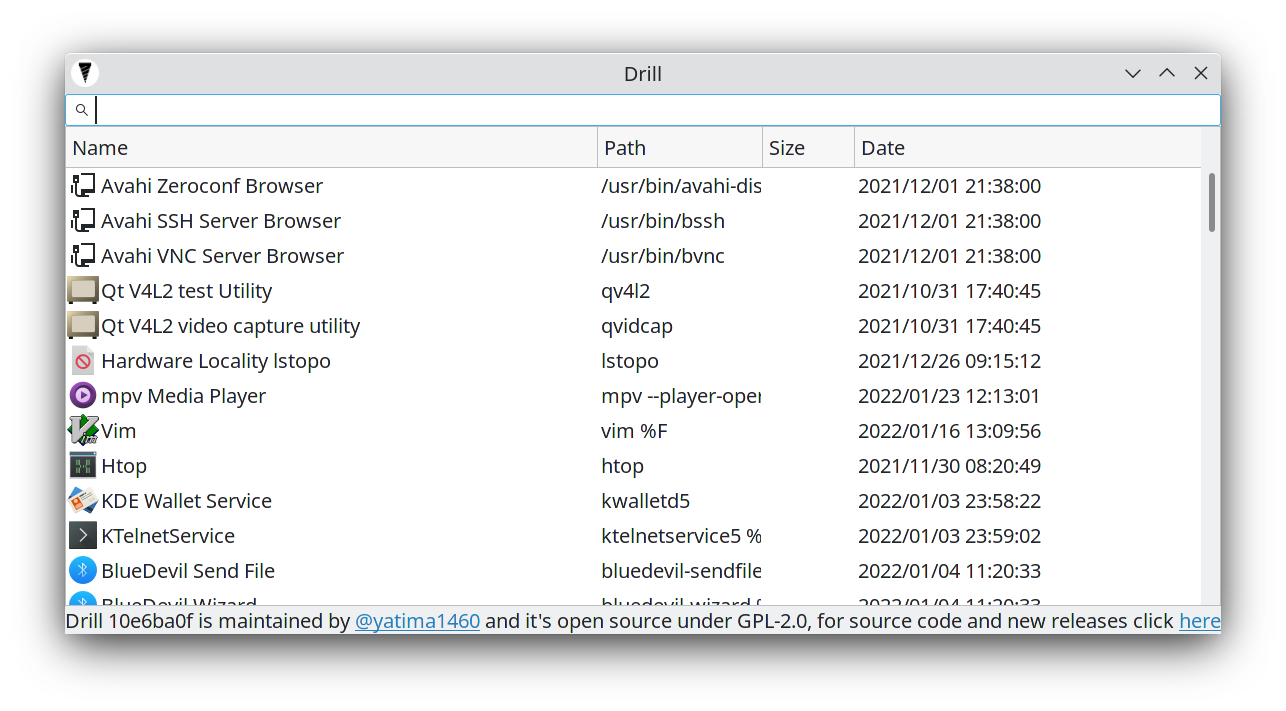
Drill is a modern file searcher for Linux that tries to fix the old problem of slow searching and indexing. Nowadays even some SSDs are used for storage and every PC has nearly a minimum of 8GB of RAM and quad-core; knowing this it's time to design a future-proof file searcher that doesn't care about weak systems and uses the full multithreaded power in a clever way to find your files in the fastest possible way.
-
Heuristics: The first change was the algorithm, a lot of file searchers use depth-first algorithms, this is a very stupid choice and everyone that implemented it is a moron, why? You see, normal humans don't create nested folders too much and you will probably get lost inside "black hole folders" or artificial archives (created by software); a breadth-first algorithm that scans your hard disks by depth has a higher chance to find the files you need. Second change is excluding some obvious folders while crawling like
Windowsandnode_modules, the average user doesn't care about .dlls and all the system files, and generally even devs too don't care, and if you need to find a system file you already know what you are doing and you should not use a UI tool. -
Clever multithreading: The second change is clever multithreading, I've never seen a file searcher that starts a thread per disk and it's 2019. The limitation for file searchers is 99% of the time just the disk speed, not the CPU or RAM, then why everyone just scans the disks sequentially????
-
Use your goddamn RAM: The third change is caching everything, I don't care about your RAM, I will use even 8GB of your RAM if this provides me a faster way to find your files, unused RAM is wasted RAM, even truer the more time passes.
Read the Issues and check the labels for high priority ones
-
Backend
- settings in .config/drill-search
- Commas in numbers strings
- Correct separator based on current system internationalization
- AM/PM time base
- 1 Threadpool per mount point
- 1 Threadpool PER DISK if possible
- NVM could benefit when multiple threads are run for the same disk?
- Metadata searching and new tokens (mp3, etc...)
- No GC in Backend
-
ncurses
-
GTK
- Open containing folder with right click
- Alternate row colors
- Error messagebox if opening file fails
- .rpm
- Snap
- Flatpak
- Drag and drop?
This project exists thanks to all the people who contribute. [Contribute].

Become a financial contributor and help us sustain our community. [Contribute]

Support this project with your organization. Your logo will show up here with a link to your website. [Contribute]