

Estimate temperature values of Large Language Models from semantic similarity of generated text
Is it possible to infer the temperature parameter value used by an LLM from only the generated text?
Probably yes.
Similarity between generated texts with same temperature level (various colors) from the prompt:
"What will technology look like in 2050?"
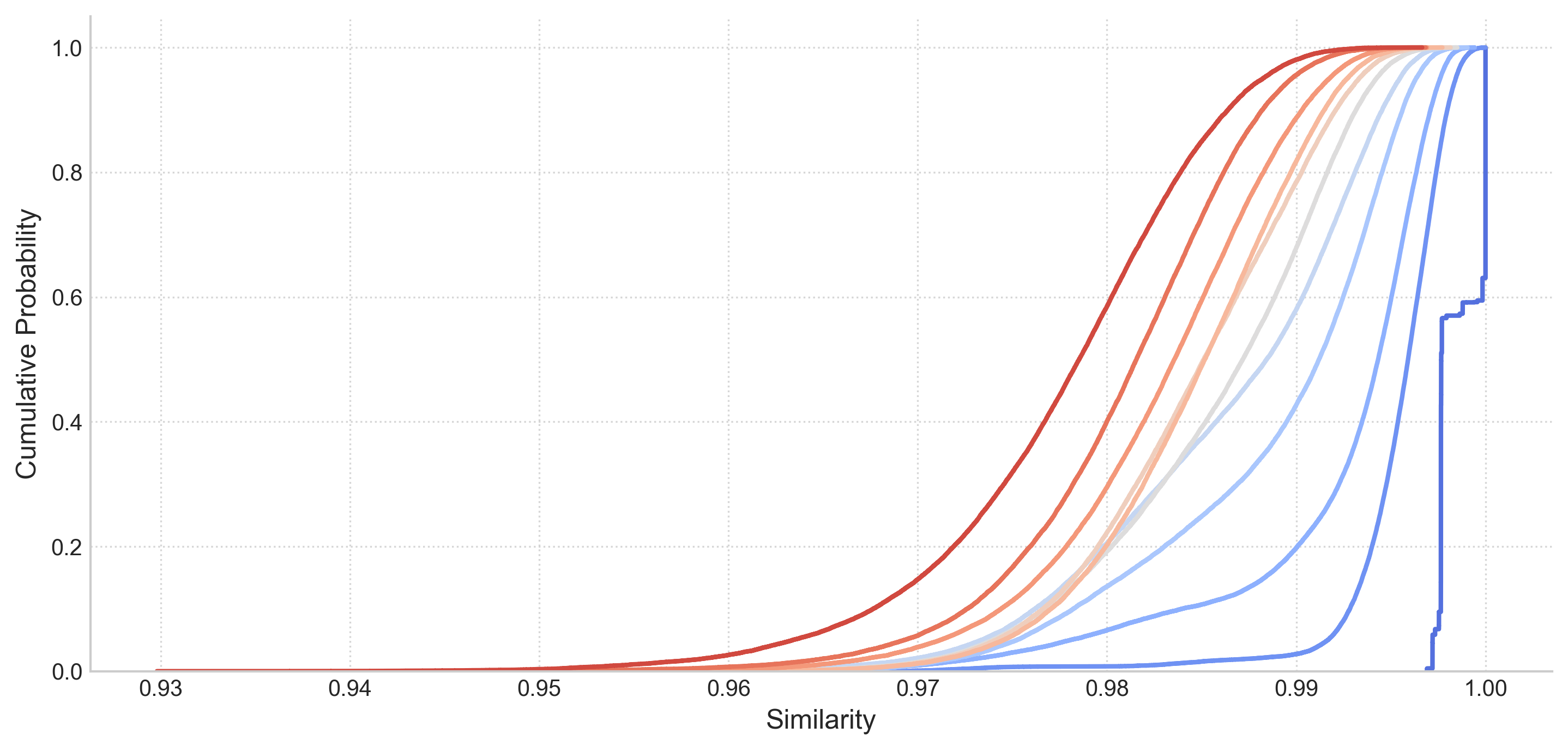
LLM Thermometer uses semantic similarity between multiple responses to estimate temperature:
- Generation: Produce multiple responses from an LLM using the same prompt
- Similarity Analysis: Measure semantic similarity between responses
- Temperature Estimation: Infer temperature based on response diversity
- Higher temperature → More diverse responses (lower similarity)
- Lower temperature → More consistent responses (higher similarity)
The reports, hosted on GitHub Pages, contains experiments metadata, charts, and tables.
# Set required environment variables
export LLM_API_KEY="your_api_key"
export LLM_BASE_URL="https://api.provider.com/v1"
export EMB_API_KEY="your_embedding_api_key"
export EMB_BASE_URL="https://api.provider.com/v1"# Generate samples
llm-thermometer generate \
--language-model "model-name" \
--prompt "What will technology look like in 2050?" \
--samples 32 \
--data-dir ./data \
--temperature 0.7 \
# Measure semantic similarity
llm-thermometer measure \
--embedding-model "embedding-model-name" \
--data-dir ./data
# Generate report
llm-thermometer report \
--data-dir ./data \
--docs-dir ./docs
# Or using Makefile...
make generate
make measure
make report
make docsThe preferred way to install llm-thermometer is using uv (although you can also use pip).
# Clone the repository
git clone https://github.com/S1M0N38/llm-thermometer.git
cd llm-thermometer
# Create a virtual environment
uv init
# Install the package
uv syncIf you have a GPU available, you can run both the Language Model and embedding model locally using docker-compose:
# Set HF_HOME environment variable for model caching
export HF_HOME="/path/to/huggingface/cache"
# Start the models
docker-compose up -d
# Language model will be available at http://localhost:41408
# Embedding model will be available at http://localhost:41409- Python 3.12+
- OpenAI-compatible API endpoints (
/chat/completionsand/embeddings) - NVIDIA GPU (for local deployment with docker-compose)
This research project is still in its early stages, and I welcome any feedback, suggestions, and contributions! If you're interested in discussing ideas or have questions about the approach, please start a conversation in GitHub Discussions.
For detailed information on setting up your development environment, understanding the project structure, and the contribution workflow, please refer to CONTRIBUTING.md.