title: "Lezione 12: Metodi Monte Carlo" author:
- "Leonardo Carminati"
- "Maurizio Tomasi" date: "A.A. 2021−2022" lang: it-IT header-includes: <script src="./fmtinstall.js"></script> ...
[La pagina con la spiegazione originale dell'esercizio si trova qui: https://labtnds.docs.cern.ch/Lezione12/Lezione12/]
In questa lezione vedremo una applicazione delle tecniche Monte Carlo per la simulazione di una delle esperienze dei laboratori di fisica. Come vedremo, la simulazione ci aiuterà a capire meglio il comportamento dell'apparato sperimentale, permettendoci per esempio di stimare l'incertezza attesa sulle grandezze da misurare.
Esercizio 11.0 - Simulazione dell'esperienza dello spettrometro a prisma (da consegnare) {#esercizio-11.0}
La dipendenza dell'indice di rifrazione dalla lunghezza d'onda della luce incidente viene descritta dalla legge di Cauchy:
dove
L'esperienza dello spettrometro a prisma si propone di misurare l'indice di rifrazione del materiale di un prisma per le diverse lunghezze d'onda di una lampada al mercurio per determinare i parametri

La misura sperimentale consiste nella determinazione delle seguenti quantità:
#. L'angolo corrispondente al fascio non deflesso in assenza del prisma
#. L'angolo corrispondente alla deviazione minima della riga del giallo
#. L'angolo corrispondente alla deviazione minima della riga del viola
L'analisi dei dati consiste nella seguente procedura:
#. determinazione degli angoli di deviazione minima:
$$
\begin{aligned}
\delta_m(\lambda_1) &= \theta_m(\lambda_1) - \theta_0,\\
\delta_m(\lambda_2) &= \theta_m(\lambda_2) - \theta_0.\\
\end{aligned}
$$
#. calcolo degli indici di rifrazione
$$
n(\lambda) = \frac{\sin\frac{\delta_m(\lambda) + \alpha}2}{\sin\frac\alpha2}.
$$
#. calcolo dei parametri A e B dalle formule
$$
\begin{aligned}
A &= \frac{\lambda_2^2 n^2(\lambda_2) - \lambda_1^2 n^2(\lambda_1)}{\lambda_2^2 - \lambda_1^2},\\
B &= \frac{n^2(\lambda_2) - n^2(\lambda_1)}{\frac1{\lambda_2^2} - \frac1{\lambda_1^2}}.
\end{aligned}
$$
La simulazione della misura parte dall'assumere dei valori verosimili dei parametri della legge di Cauchy e determinare come questi si traducono in quantità osservabili. A partire da queste quantità osservabili simuliamo una misura aggiungendo una perturbazione gaussiana ai valori nominali e ne determiniamo l'impatto sulle grandezze da misurare (
Nell'esperimento, l'unico tipo di grandezze misurate sono gli angoli, per cui possiamo assumere un'incertezza uguale per tutte le misure angolari e pari a
Per costruire la nostra simulazione, procediamo per gradi:
-
Costruire una classe
EsperimentoPrismacon le seguenti caratteristiche:-
come data membri deve avere sia i valori veri che i valori misurati di tutte le quantità ed in più un generatore di numeri casuali
RandomGen(vedi lezione 10); -
nel costruttore deve definire tutti i valori “veri” delle quantità misurabili a partire dai parametri
$A$ ,$B$ ,$\alpha$ e dalle lunghezze d'onda.
N.B.: il valore di
$\theta_0$ è arbitrario, ma, una volta definito, i$\theta_m$ sono fissati. -
-
Aggiungere un metodo `Esegui()`` che effettua la misura sperimentale e determina dei valori misurati di
$\theta_0$ ,$\theta_m(\lambda_1)$ ,$\theta_m (\lambda_2)$ ;N.B.: il valore misurato di un angolo si ottiene estraendo un numero distribuito in maniera gaussiana intorno al suo valore “vero” nella simulazione e deviazione standard
$\sigma_\theta$ . -
Aggiungere alla classe un metodo
Analizza()che, a partire dalle pseudomisure, svolga l'analisi dei dati sino alla determinazione di$A$ e$B$ (misurati). -
Implementare i metodi necessari per accedere ai valori dei data membri, sia quelli “veri” sia quelli misurati.
Scrivere un programma che esegua 10000 volte l'esperimento, faccia un istogramma dei valori misurati, e calcoli media e deviazione standard di tali valori. Per il calcolo di medie e deviazioni standard potete decidere di immagazzinare i dati in un contenitore std::vector e utilizzare le funzioni sviluppate nelle prime lezioni, oppure se usate ROOT potete usare le sue funzionalità come mostrato qui (ricordatevi però di aggiungere histo.StatOverflows(kTRUE); in modo da forzare l'utilizzo di eventuali underflow e overflow per calcoli statistici).
In particolare, è utile studiare le seguenti distribuzioni:
#. Distribuzione delle differenze tra i valori misurati e quelli attesi per
#. Distribuzione della differenza tra i valori misurati e quelli attesi di
#. Distribuzione della differenza tra i valori misurati e quelli attesi di
#. Distribuzione delle differenza tra i valori misurati e quelli attesi di
In caso provate a confrontare l'errore stimato su
La classe EsperimentoPrisma deve contenere al suo interno un generatore di numeri casuali per la simulazione del processo di misura, tutti i parametri che definiscono l'esperimento e, per le quantità misurate, sia il valore assunto sia il valore ottenuto dal processo di misura ed analisi dati dell'esperimento.
Il file header potrà pertanto essere fatto così:
// File prisma.h
#pragma once
#include "randomgen.h"
class EsperimentoPrisma {
public:
EsperimentoPrisma(unsigned int seed);
~EsperimentoPrisma() { }
void Esegui();
void Analizza();
double getAmis() { return m_A_misurato; };
private:
// generatore di numeri casuali
RandomGen m_rgen;
// parametri dell'apparato sperimentale
double m_lambda1, m_lambda2, m_alpha, m_sigmat;
// valori delle quantita' misurabili :
// input : valori assunti come ipotesi nella simulazione
// misurato : valore dopo la simulazione di misura
double m_A_input, m_A_misurato;
double m_B_input, m_B_misurato;
double m_n1_input, m_n1_misurato;
double m_n2_input, m_n2_misurato;
double m_dm1_input, m_dm1_misurato;
double m_dm2_input, m_dm2_misurato;
double m_th0_input, m_th0_misurato;
double m_th1_input, m_th1_misurato;
double m_th2_input, m_th2_misurato;
};N.B.: in questo header mancano i metodi di tipo Get per accedere ai data membri.
La configurazione dell'esperimento, con il calcolo di tutti i valori 'veri' per le quantità misurabili, può venire fatta nel costruttore della classe, che in questo caso risulta più complicato del solito:
#include "prisma.h"
#include <cmath>
EsperimentoPrisma::EsperimentoPrisma(unsigned int seed)
: m_rgen{seed}, m_lambda1{579.1E-9}, m_lambda2{404.7E-9},
m_alpha{60. * numbers::pi / 180.}, m_sigmat{0.3E-3}, m_A_input{2.7},
m_B_input{60000E-18} {
// calcolo degli indici di rifrazione attesi
m_n1_input = std::sqrt(m_A_input + m_B_input / (m_lambda1 * m_lambda1));
m_n2_input = std::sqrt(m_A_input + m_B_input / (m_lambda2 * m_lambda2));
// theta0 e' arbitrario, scelgo numbers::pi/2.
m_th0_input = numbers::pi / 2.;
// determino theta1 e theta2
m_dm1_input = 2. * std::asin(m_n1_input * sin(0.5 * m_alpha)) - m_alpha;
m_th1_input = m_th0_input + m_dm1_input;
m_dm2_input = 2. * std::asin(m_n2_input * sin(0.5 * m_alpha)) - m_alpha;
m_th2_input = m_th0_input + m_dm2_input;
}Notate l'uso della lista di inizializzazione nel costruttore: questa permette di inizializzare direttamente i valori dei data membri anziché procedere all'assegnazione dei valori nel costruttore dopo che i data membri siano stati costruiti. Nel nostro caso particolare diventa utile per inizializzare l'oggetto m_rgen invocando il costruttore opportuno (altrimenti avrebbe usato il costruttore senza argomenti, che nel nostro caso non esiste). Potete trovare una buona spiegazione dell'utilizzo delle liste di inizializzazione qui, ma erano state già spiegate durante le esercitazioni.
Per verificare le correlazioni tra due variabili, è utile utilizzare istogrammi bidimensionali, in cui i canali sono definiti da range di valori sia di una variabile che dell'altra.
Per costruire questi istogrammi, si può usare un classico «scatter plot», identico a un plot normale ma in cui non si congiungono i punti con linee. In gplot++ è sufficiente usare lo stile Gnuplot::LineStyle::POINTS:
Gnuplot plt{};
plt.set_xlabel("Variabile X");
plt.set_ylabel("Variabile Y");
// `x` e `y` sono due vettori che contengono le due variabili
// di cui si vuole studiare la correlazione
plt.plot(x, y, "", Gnuplot::LineStyle::POINTS);
plt.show();In ROOT è possibile usare lo stesso trucco, oppure produrre un istogramma 2D tramite la classe TH2F di ROOT. Questa ha un costruttore che premette di dividere in canali sia la coordinata
TH2F::TH2F(char * nome, char * titolo,
int canali_x, double xmin, double xmax,
int canali_y, double ymin, double ymax);La classe TH2F ha gli stessi metodi Fill e Draw della classe TH1F; l'unica differenza è che ora Fill ha bisogno della coppia completa di valori per decidere il canale in cui viene collocato l'evento:
TH2F::Fill(double x, double y);Il coefficiente di correlazione
Nella seguente tabella sono riportati i valori numerici attesi per le varie quantità ed i grafici ottenuti per una simulazione. Si noti come le varie quantità sono fortemente correlate.
| Parametri | Grafici |
| $$ \begin{aligned} \theta_0 &= 1.5708\quad\text{(arbitrario)},\\ \theta_1 &= 2.5494,\\ \theta_2 &= 2.6567,\\ \sigma(\theta_i) &= 0.0003,\quad i = 0, 1, 2. \end{aligned} $$ |  |
| $$ \begin{aligned} \delta_{m, 1} &= 0.97860\,\text{rad}\\ \delta_{m, 2} &= 1.08594\,\text{rad}\\ \sigma(\delta_{m, i}) &= 0.00043\,\text{rad},\\ \rho(\delta_{m, 1}, \delta_{m, 2}) &= 50\,\% \end{aligned} $$ | 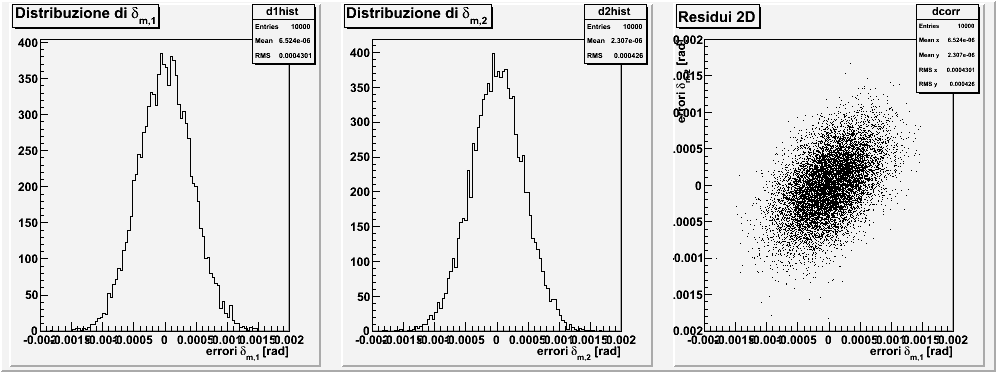 |
| $$ \begin{aligned} n_1 &= 1.69674\\ \sigma(n_1) &= 0.00022\\ n_2 &= 1.75110\\ \sigma(n_2) &= 0.00021\\ \rho(n_1, n_2) &= 50\,\%. \end{aligned} $$ | 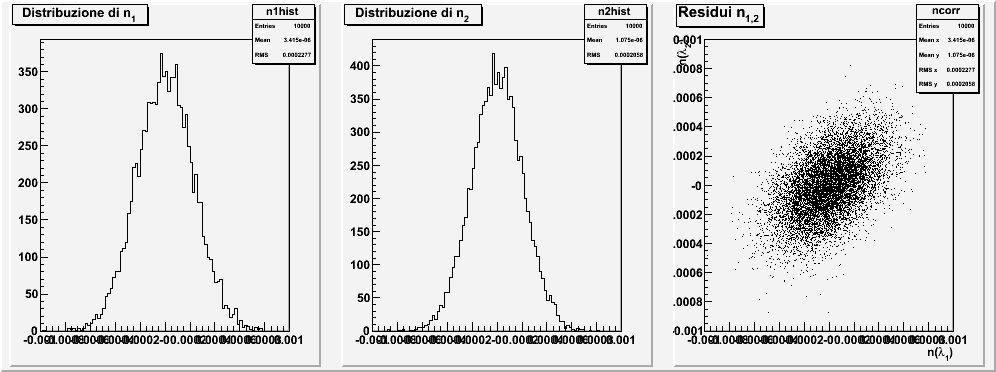 |
| $$ \begin{aligned} A &= 2.70002\\ \sigma(A) &= 0.0013\\ B &= 60000\,\text{nm}^2\\ \sigma(B) &= 240\,\text{nm}^2\\ \rho(A,B) &= -87\,\%. \end{aligned} $$ | 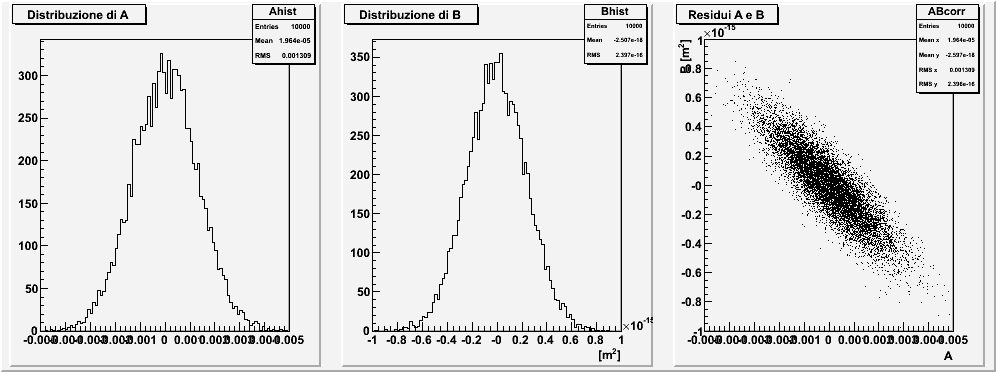 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Svolgere il tema d'esame sulla simulazione di un esperimento per la misura della viscosità di un materiale: preappello del gennaio 2009, esercizio 6.
- Tantissime persone (il ~30%) non calcolano il coefficiente di correlazione come richiesto dall'esercizio. A quanto pare alcuni studenti credono che il grafico che mostra la correlazione sia sufficiente; il testo invece vi chiede di implementare proprio il calcolo della formula!
- Non usate
TH1Fdi ROOT per calcolare medie e deviazioni standard, ma affidatevi alle funzioni che avete implementato nelle prime tre lezioni. Il problema diTH1Fè che richiede di specificare l’intervallo entro cui considerare i campioni, ed esclude quelli che stanno al di fuori. Non è un grosso problema nello svolgimento di questo esercizio, ma quando in un tema d’esame si richiede di simulare un esperimento, gli studenti copiano il codice sorgente dell’esercizio 11.0 e si dimenticano di aggiornare gli estremi, oppure li aggiornano andando a naso e specificandoli troppo stretti. Le funzioni che avete scritto nelle prime tre lezioni di laboratorio non hanno questo fastidioso problema, e sono quindi molto più sicure da usare.