Managed service for streaming data (logs, IoT, social media, market data feeds, web clickstream) with added functionalities for Analytics and Machine Learning. AWS also offers Amazon Managed Streaming for Apache Kafka (Amazon MSK) to work with streaming data.
Low latency services to ingest and process large streams in real time. It can be replayed from 1 to 7 days.
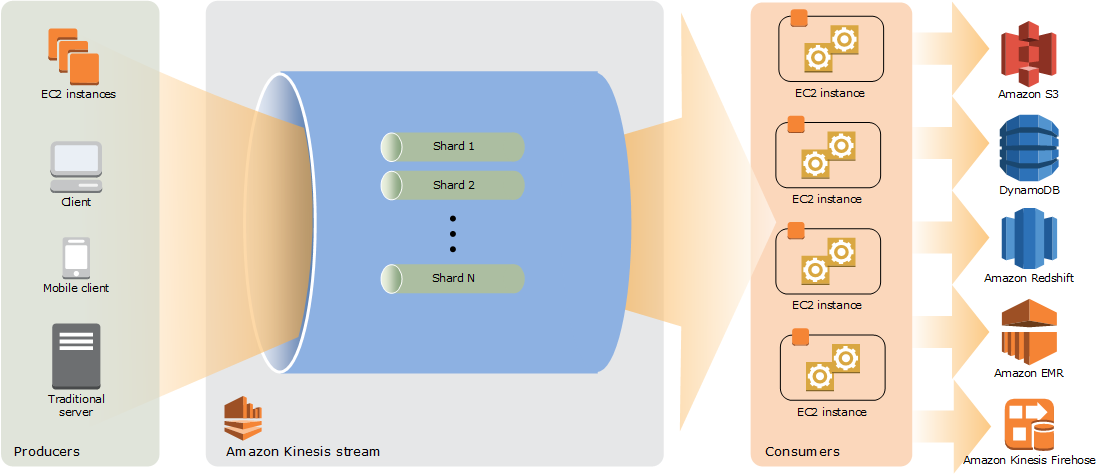
Producers > Shards (Provisioned in advance) > Consumers
*Source: https://docs.aws.amazon.com/streams/latest/dev/key-concepts.html
A producer puts data records (partition key and data blob) into a shard. The consumer Kinesis Data Streams application are created using the Kinesis Client Library which can run on EC2 instances. AWS Lambda, Kinesis Data Analytics or Data Firehose can also be used as consumers.
Complex processing can be configured with Directed Acyclic Graphs (DAGs) of Kinesis Data Streams.
Quotas: No limit on the number of shards or streams. A single shard can ingest up to 1 MB of data per second (including partition keys) or 1,000 records per second for writes.
Offers real time analytics capabilities using SQL or Apache Flink, including time series analytics, real-time dashboards and metrics.
Workflow: Input stream + Reference tables (S3) > Analytics > Output stream + Errors
Includes machine learning models to analyze the streaming data:
- Random Cut Forest: For anomaly detection
- Hotspots: Locate dense regions
Destinations for the output stream are Amazon Kinesis Data Firehose, AWS Lambda, and Amazon Kinesis Data Streams.
For SQL, Kinesis Analytics supports ANSI 2008 SQL standard with extensions, which include specific functions for streams as ROWTIME with the timestamp the record was inserted to perform time-based windowed queries. It also supports continuous queries, which are useful to trigger alerts.
With Apache Flink, you can code in Scala or Java. AWS hosts and scales the service offering the same functionalities. Flink architecture is based on connectors:
- Source: read external data
- Sink: write to external locations
- Operator: process data
Ingest data in near real-time, transform it (CSV/JSON to Parquet/ORC or through AWS Lambda) and storage it in AWS services: S3 (Support compression (GZIP, ZIP)), Redshift, Elasticsearch (Amazon ES), Splunk.
Data is sent to a Kinesis Data Firehose delivery stream from Kinesis data stream, the Kinesis Agent, the Kinesis Data Firehose API, CloudWatch Logs or Events, or AWS IoT.
For data transformations, Data Firehose can invoke a specified Lambda function asynchronously with buffered data (buffer size can be configured with BufferSizeInMBs) before sending to the final destination.
Firehose needs less configuration than Streams (shards), therefore, it's the best option if not custom applications are involved.
Real-time video processing or batch-oriented video analytics.
Workflow: Producer (i.e. security camera, AWS DeepLens) > Consumer (Any DL model on EC2, AWS SageMaker, Amazon Rekognition video)