This repository was archived by the owner on Oct 1, 2020. It is now read-only.
Qnnpack accuracy very poor on unet model #73
Comments
|
Question - typically how many epochs are good enough for QAT fine tuning? And do we need to supply loads of images for training (like say 5000), or few can suffice (say 100)? |
|
Question - suppose I performed QAT for say n epochs. Then (before calling |
|
I raised this issue on discussion forum as well. Please refer here for more details on the issue. |
Sign up for free
to subscribe to this conversation on GitHub.
Already have an account?
Sign in.
I am using Unet model for semantic segmentation. I pass a batch of images to the model. The model is expected to output 0 or 1 for each pixel of the image (depending upon whether pixel is part of person object or not). 0 is for background, and 1 is for foreground.
I am trying to quantize the Unet model with Pytorch quantization apis for ARM architecture. I chose Qnnpack as quantization configuration. However the model accuracy is very poor for both Post training static quantization as well as QAT. The output is always a complete black image i.e. contains only background, no foreground for the person object. The model outputs bX2X224X224 i.e. batch_size X 2 channels (one for forground and one for background) X height X width.
Following is the output values for the center pixels of images - with original model and with quantized model.
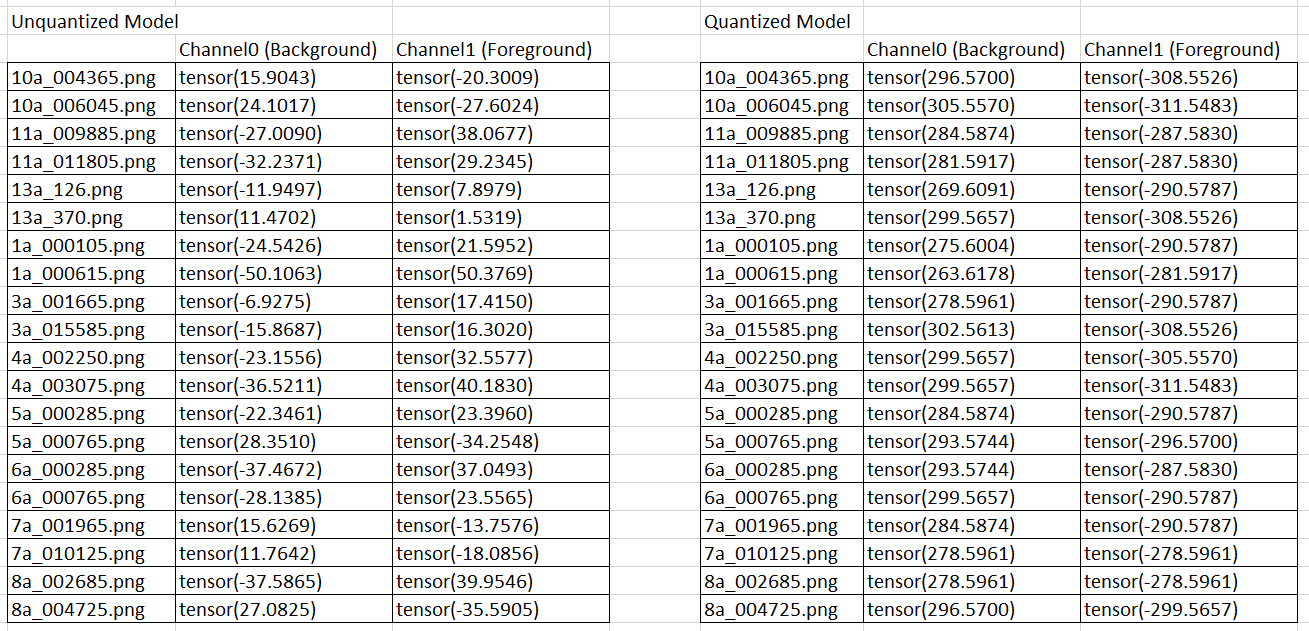
As seen, the original model has varying output values. Hence when we apply Softmax on dim=1 (i,e, Channel dimension), we get some pixels as 0 and some as 1. This is as per expectation. However, the quantized model always outputs high positive for background and high negative for foreground channel. After applying softmax, all the pixels are background pixels, and the output is black images.
I need some help to find why this is happening. Is it a bug in qnnpack quantization routine?
The model source code is available at here. I used pretrained version of Unet with MobileNetV2 as backbone (check benchmark section in the readme from the source code link) - see here.
I first tried with Fbgemm configuration, and it worked fine in terms of accuracy - no major loss. However, when tried with qnnpack, I face above issues. Following is my code for QAT.
Am I missing anything?
One issue that we did encounter is that the upsampling layers of Unet use nn.ConvTranspose2d which is not supported for quantization. Hence before this layer, we need to dequantize tensors, apply nn.ConvTranspose2d, and then requantize for subsequent layers. Can this be reason for lower accuracy?
The following is the model after QAT training is completed for 30 epochs . . .
Any help is highly appreciated - thanks.
The text was updated successfully, but these errors were encountered: