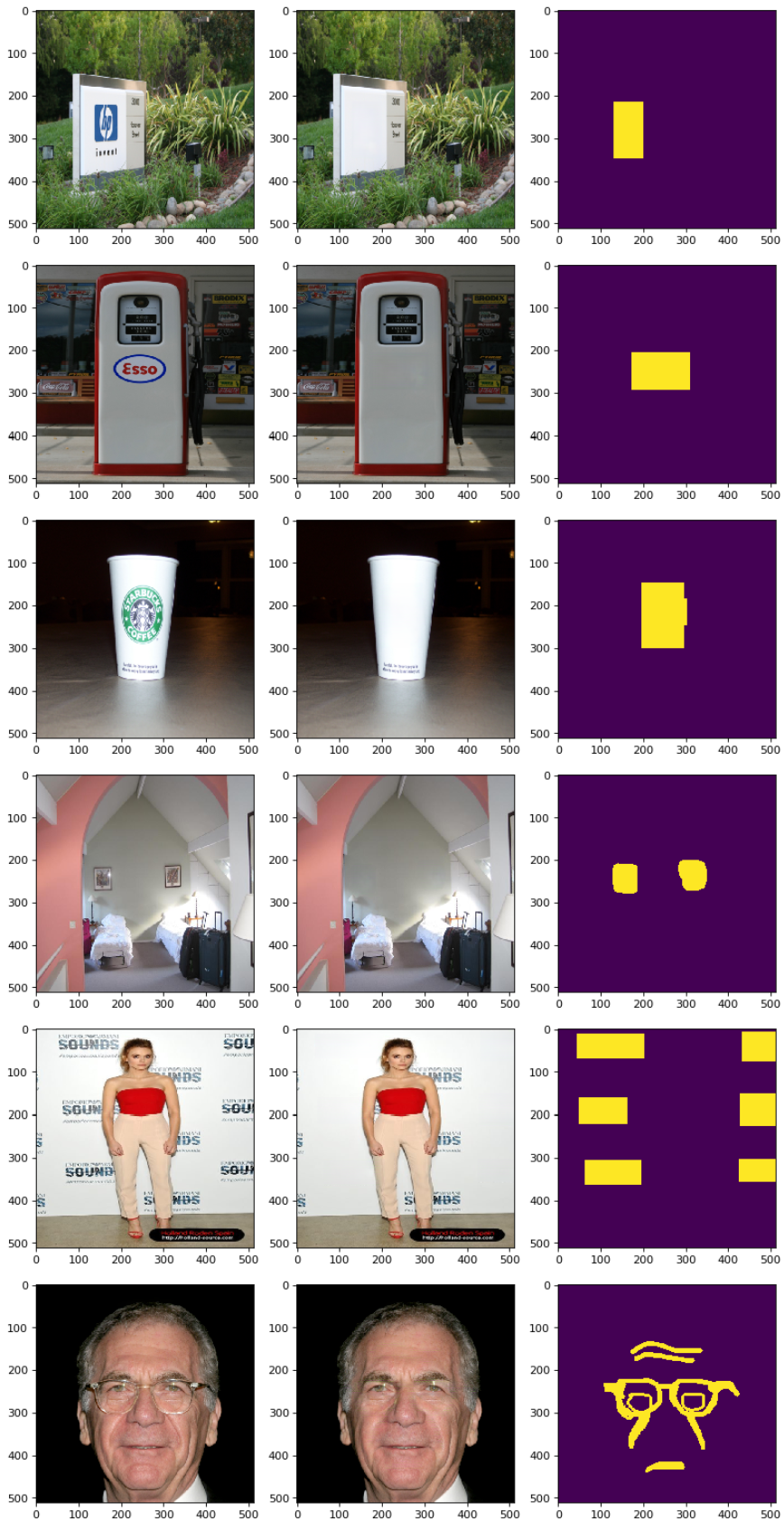
本项目使用Paddle框架复现了AOT GAN模型,该模型通过聚合不同膨胀率的空洞卷积学习到的图片特征,刷出了inpainting任务的新SOTA。模型推理效果如下:
论文: Aggregated Contextual Transformations for High-Resolution Image Inpainting
参考repo: https://github.com/megvii-research/NAFNet
在此非常感谢Yanhong Zeng, Jianlong Fu, Hongyang Chao, and Baining Guo等人贡献的https://github.com/megvii-research/NAFNet,提高了本repo复现论文的效率。
aistudio体验教程: https://aistudio.baidu.com/aistudio/projectdetail/4567435
模型训练使用了 Place365Standard 数据集的训练集图片,以及 NVIDIA Irregular Mask Dataset 数据集的测试集掩码图片。
- 数据集大小:
- Place365Standard 训练集:130G,160万张长或宽最小为 512 像素的图片。
- NVIDIA Irregular Mask Dataset 测试集:45M,12000张尺寸为 512 x 512 的不规则掩码图片。
- 数据集下载链接:
- Place365Standard(下载地址)
- NVIDIA Irregular Mask Dataset (下载地址)
- Place365Standard 的验证集和 NVIDIA Irregular Mask Dataset 的测试集已经搬运到了 AI Studio 上,(下载地址)使用时请遵守发布者的版权规范。
- 数据格式:
- 模型训练时使用 NVIDIA Irregular Mask Dataset 测试集的全部 12000 张图片,模型验证时,按照指标规范只使用其中的 2000 张像素擦除率在 20%~30%之间的掩码图片。
- 模型精度:
| 名称 | 数值 |
|---|---|
| 论文精度 | Places365-val(20-30% ): PSNR=26.03, SSIM=0.890 |
| 参考代码精度 | Places365-val(20-30% ): PSNR=26.03, SSIM=0.890 |
| 本repo复现精度 | Places365-val(20-30% ): PSNR=26.04001, SSIM=0.89011 |
| 生成器预训练参数(58M) | g.pdparams |
| 预训练 check point(191M) | output.zip |
| 预训练日志 | log.txt |
| VGG19模型预训练参数(80M) | vgg19feats.pdparams |
注:参考代码使用 batch size = 8 设置,训练了100万个iteration。复现代码先使用 batch size = 8 设置,训练了近 6.32 万个iteration,然后采用 batch size = 24 设置,训练了近 25.2万个iteration。其余超参设定同参考代码。
首先介绍下支持的硬件和框架版本等环境的要求,格式如下:
-
硬件:GPU 显存 >= 40GB(batch size=8设定下)
-
框架:
- PaddlePaddle >= 2.3.2
安装:
python -m pip install paddlepaddle-gpu==2.3.2.post111 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html(详情参考官网安装指南)- Scikit-Image >= 0.19.3
安装:
pip install scikit-image- opencv >= 4.1.1.26
安装:
pip install opencv-contrib-python
- 训练用的图片解压到项目路径下的 dataset/train_img 文件夹内,可包含多层目录,dataloader会递归读取每层目录下的图片。训练用的mask图片解压到项目路径下的 dataset/train_mask 文件夹内。
- 验证用的图片和mask图片相应的放到项目路径下的 dataset/val_img 文件夹和 dataset/val_mask 文件夹内。
- 在前面【2. 数据集和复现精度】中提供了预训练模型的 check point 和推理模型权重,以及训练时计算 Perceptual Loss 的 VGG19 模型的预训练权重的下载地址。
- VGG19预训练权重文件 vgg19feats.pdparams 放在项目路径下的 weight 文件夹内。
- 如果继续训练,将下载的 check point 文件夹 output 解压后直接放在项目路径下。
- 如果只进行推理、验证,可以只下载生成器的预训练权重文件 g.pdparams,将其放到项目路径下的 otuput/model 文件夹内。
执行训练
cd /home/aistudio/AOT_GAN_Paddle
python -W ignore train.py # 执行参数请参考train.py脚本中的注释
- 训练过程中Paddle自动检测是否具备多卡环境,如果是则多卡并行执行训练过程。多卡训练时batch size为每张卡上训练的样本数。如果是单卡环境则执行单卡训练。
- 训练过程中生成的图片存储在项目路径下的 output/pic 文件夹中。
训练过程中日志打印迭代次数、生成器和判别器的各部分 Loss,以及耗时等等信息:(部分日志展示如下)
已经完成 [314952] 步训练,开始继续训练...
读取存储的模型权重、优化器参数...
current_step: 314953 epoch: 0 step:[0/8]g_l1: [0.23513305] g_perceptual: [0.7259111] g_style: [7.431006] g_adversal:[0.0092756]g_total: [8.401325] d_fake: [0.0572298] d_real: [0.00284055] d_total: [0.06007035] filename:dataset/train_img/Places365_val_00000007.jpg 2022-09-20 20:45:22
current_step: 314954 epoch: 0 step:[1/8]g_l1: [0.36099753] g_perceptual: [0.8445536] g_style: [8.832294] g_adversal:[0.00973949] g_total: [10.0475855] d_fake: [0.06242044] d_real: [6.546691e-05] d_total: [0.0624859] filename:dataset/train_img/Places365_val_00000003.jpg 2022-09-20 20:45:24
- 训练过程中环境、超参的设定在项目路径下的 model/config.py 文件中(验证、推理过程也使用此同一配置文件),文件内容如下:
# 设置全局变量、超参
class OPT():
def __init__(self):
super(OPT, self).__init__()
# 在AI Studio上用A100单卡训练时,设置为8(bs=8);在使用V100四卡训练时设为6(bs=6x4=24)
# self.batch_size = 6 # V100单卡、多卡训练
# self.batch_size = 8 # A100单卡训练
self.batch_size = 1
self.img_size = 512 # 生成图片尺寸
self.rates = [1, 2, 4, 8] # 各个尺度空洞卷积的膨胀率
self.block_num = 8 # 生成器中AOT模块的层数
self.l1_weight = 1 # L1 Loss的加权
self.style_weight = 250 # Style Loss的加权
self.perceptual_weight = .1 # Perceptu Loss的加权
self.adversal_weight = .01 # GAN Loss的加权
self.lrg = 1e-4 # 生成器学习率
self.lrd = 1e-4 # 判别器学习率
self.beta1 = .5 # Adam优化器超参
self.beta2 = .999 # Adam优化器超参
self.dataset_path = 'dataset' # 训练、验证数据集存放路径
self.output_path = 'output' # chenk point,log等存放路径
self.vgg_weight_path = 'weight/vgg19feats.pdparams' # vgg19 预训练参数存放路径
opt = OPT()
执行预测
%cd /home/aistudio/AOT_GAN_Paddle
!python val.py # 执行参数请参考val.py脚本中的注释
- 执行验证过程时保存的psnr和ssim指标存放在项目路径下的 output/psnr_ssim.txt 文件中。
- 验证过程中生成的图片存储在项目路径下的 output/pic_val 文件夹中。
- 验证过程中使用环境、超参的设定与训练使用同一配置文件,是项目路径下的 model/config.py 文件。
验证过程会打印生成图片与原图片比对的 psnr 和 ssim 值,以及它们的累计均值:(部分日志展示如下)
已经完成 [314952] 步训练,开始验证...
current_step: 0 filename: dataset/val_img/Places365_val_00000001.jpg psnr: 19.973892724416423 ssim: 0.8249856740962208 psnr mean: 19.973892724416423 ssim mean: 0.8249856740962208 2022-09-20 10:03:57
current_step: 100 filename: dataset/val_img/Places365_val_00000101.jpg psnr: 22.30029094468997 ssim: 0.8564899927420897 psnr mean: 25.270560812420875 ssim mean: 0.8898851025092125 2022-09-20 10:04:14
进行模型预测使用以下代码:
- 输入图片的存放文件夹为项目路径下的 'dataset/demo_img/'
- 输入mask路径为 'dataset/demo_mask/'
- 预测结果逐一使用 matplotlib 库输出
%cd /home/aistudio/AOT_GAN_Paddle
import numpy as np
import os
import time
from PIL import Image
import paddle
from paddle.vision.transforms import Resize
from model.config import opt
from model.model import InpaintGenerator
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
img_path = 'dataset/demo_img/'
mask_path = 'dataset/demo_mask/'
for _, _, files in os.walk(img_path):
pics = np.sort(np.array(files))
break
for _, _, files in os.walk(mask_path):
masks = np.sort(np.array(files))
break
def predict(img_path, mask_path, g):
# 读取原图片与mask掩码图片并进行resize、格式转换
img = Image.open(img_path)
mask = Image.open(mask_path)
img = Resize([opt.img_size, opt.img_size], interpolation='bilinear')(img)
mask = Resize([opt.img_size, opt.img_size], interpolation='nearest')(mask)
img = img.convert('RGB')
mask = mask.convert('L')
img = np.array(img)
mask = np.array(mask)
img_show1 = img
img_show3 = mask
# 图片数据归一化到(-1, +1)区间,形状为[n, c, h, w], 取值为[1, 3, 512, 512]
# mask图片数据归一化为0、1二值。0代表原图片像素,1代表缺失像素。形状为[n, c, h, w], 取值为[1, 1, 512, 512]
img = (img.astype('float32') / 255.) * 2. - 1.
img = np.transpose(img, (2, 0, 1))
mask = np.expand_dims(mask.astype('float32') / 255., 0)
img = paddle.to_tensor(np.expand_dims(img, 0))
mask = paddle.to_tensor(np.expand_dims(mask, 0))
# 预测
img_masked = (img * (1 - mask)) + mask # 将掩码叠加到图片上
pred_img = g(img_masked, mask) # 用加掩码后的图片和掩码生成预测图片
comp_img = (1 - mask) * img + mask * pred_img # 使用原图片和预测图片合成最终的推理结果图片
img_show2 = (comp_img.numpy()[0].transpose((1,2,0)) + 1.) / 2.
# 显示
plt.figure(figsize=(12,4),dpi=80)
plt.subplot(1, 3, 1)
plt.imshow(img_show1)
plt.subplot(1, 3, 2)
plt.imshow(img_show2)
plt.subplot(1, 3, 3)
plt.imshow(img_show3)
plt.show()
# 初始化生成器,读取参数
g = InpaintGenerator(opt)
g.eval()
para = paddle.load(os.path.join(opt.output_path, "model/g.pdparams"))
g.set_state_dict(para)
for pic, mask in zip(pics, masks):
predict(os.path.join(img_path, pic), os.path.join(mask_path, mask), g)
运行 AI Studio 上的一键自动化测试项目:https://aistudio.baidu.com/aistudio/projectdetail/4567435
本项目的发布受Apache 2.0 license许可认证。
@inproceedings{yan2021agg, author = {Zeng, Yanhong and Fu, Jianlong and Chao, Hongyang and Guo, Baining}, title = {Aggregated Contextual Transformations for High-Resolution Image Inpainting}, booktitle = {Arxiv}, pages={-}, year = {2020} }