리액티브 프로그래밍은 데이터 스트림과 변경 사항 전파를 중심으로 하는 비동기 프로그래밍 패러다임이다. 간단하게 말하면 데이터와 데이터 스트림에 영향을 미치는 모든 변경 사항을 관련된 모든 당사자들, 예를 들면 최종 사용자나 컴포넌트, 하위 구성 요소, 또는 어떻게든 연결돼 있는 다른 프로그램 등에게 전파하는 프로그램을 리액티브 프로그램이라고 한다.
변화의 전파와 데이터 흐름과 관련된 선언적 프로그래밍 패러다임이다.
- 변화의 전파와 데이터 흐름: 데이터가 변경될 때마다 이벤트를 발생시켜 데이터를 계속적으로 전달한다
- 선언적 프로그래밍: 실행할 동작을 구체적으로 명시하는 프로그래밍과 달리 선언형 프로그래밍은 단순히 목표를 선언한다.
class Test {
@Test
void 선언형프로그래밍() {
// List에 있는 숫자들 중에 6보다 큰 홀수들의 합계를 구하시오
final List<Integer> numbers = Arrays.asList(1, 3, 21, 10, 8, 11);
int sum = 0;
for (Integer number : numbers) {
if (number > 6 && (number % 2 != 0)) {
sum += number;
}
}
System.out.println("명령형 프로그래밍 사용 : " + sum);
}
@Test
void 선언적프로그래밍() {
// List에 있는 숫자들 중에 6보다 큰 홀수들의 합계를 구하시오
final List<Integer> numbers = Arrays.asList(1, 3, 21, 10, 8, 11);
final int sum = numbers.stream()
.filter(number -> number > 6 && (number % 2 != 0))
.mapToInt(number -> number)
.sum();
System.out.println("명령형 프로그래밍 사용 : " + sum);
}
}데이터의 변화가 발생했을 때 변경이 발생한 곳에서 데이터를 보내주는 방식
- RTC
- 소켓 프로그래밍
- DB Trigger
- Spring ApplicationEvent
- 스마트폰의 Push 메시지
변경된 데이터가 있는지 요청을 보내고 질의하고 변경된 데이터를 가져오는 방식
- 클라이언트 요청 & 서버 응답 방식의 애플리케이션
- Java와 같은 절차형 프로그래밍 언어
- Observable: 데이터 소스
- 리액티브 연산자: 데이터 소스를 처리하는 함수
- 스케줄러: 스레드 관리자
- Subscriber: Observable이 발행하는 데이터를 구독하는 구독자
- 함수형 프로그래밍: RxJava에서 제공하는 연산자 함수를 사용
@Test
void 리액티브프로그래밍() throws InterruptedException {
Observable.just(100, 200, 300, 400, 500)
// .doOnNext(data -> System.out.println(getThreadNAme() + " : doOnNext() :" + data))
// .subscribeOn(Schedulers.io())
// .observeOn(Schedulers.computation())
.filter(number -> number > 300)
.subscribe(num -> System.out.println(getThreadNAme() + " : result : " + num));
// Thread.sleep(500);
// 결과
//Test worker : result : 400
//Test worker : result : 500
}just를 통해서 데이터를 발행한다filter를 통해서 300 이상인 것을 필터링한다고 선언한다subscribe발행된 데이터, 필터링 된 데이터를 출력한다.- 데이터를 발행 > 데이터를 가공 > 데이터를 구독해서 처리
Test worker스레드에서 실행된다.
@Test
void 리액티브프로그래밍() throws InterruptedException {
Observable.just(100, 200, 300, 400, 500)
.doOnNext(data -> System.out.println(getThreadNAme() + " : doOnNext() :" + data))
// .subscribeOn(Schedulers.io())
// .observeOn(Schedulers.computation())
.filter(number -> number > 300)
.subscribe(num -> System.out.println(getThreadNAme() + " : result : " + num));
Thread.sleep(500);
// Test worker : doOnNext() :100
// Test worker : doOnNext() :200
// Test worker : doOnNext() :300
// Test worker : doOnNext() :400
// Test worker : result : 400
// Test worker : doOnNext() :500
// Test worker : result : 500
}- 동일하게
Test worker스레드에서 실행 doOnNext()데이터가 발행될 때마다 실행된다.
@Test
void 리액티브프로그래밍() throws InterruptedException {
Observable.just(100, 200, 300, 400, 500)
.doOnNext(data -> System.out.println(getThreadNAme() + " : doOnNext() :" + data))
.subscribeOn(Schedulers.io())
// .observeOn(Schedulers.computation())
.filter(number -> number > 300)
.subscribe(num -> System.out.println(getThreadNAme() + " : result : " + num));
// Thread.sleep(500);
// RxCachedThreadScheduler-1 : doOnNext() :100
// RxCachedThreadScheduler-1 : doOnNext() :200
// RxCachedThreadScheduler-1 : doOnNext() :300
// RxCachedThreadScheduler-1 : doOnNext() :400
// RxCachedThreadScheduler-1 : result : 400
// RxCachedThreadScheduler-1 : doOnNext() :500
// RxCachedThreadScheduler-1 : result : 500
}subscribeOn()를 실행하게 되면RxCachedThreadScheduler스레드에서 실행된다.
@Test
void 리액티브프로그래밍() throws InterruptedException {
Observable.just(100, 200, 300, 400, 500)
.doOnNext(data -> System.out.println(getThreadNAme() + " : doOnNext() :" + data))
.subscribeOn(Schedulers.io())
.observeOn(Schedulers.computation())
.filter(number -> number > 300)
.subscribe(num -> System.out.println(getThreadNAme() + " : result : " + num));
// Thread.sleep(500);
// RxCachedThreadScheduler-1 : doOnNext() :100
// RxCachedThreadScheduler-1 : doOnNext() :200
// RxCachedThreadScheduler-1 : doOnNext() :300
// RxCachedThreadScheduler-1 : doOnNext() :400
// RxCachedThreadScheduler-1 : doOnNext() :500
// RxComputationThreadPool-1 : result : 400
// RxComputationThreadPool-1 : result : 500
}subscribeOn()데이터의 발행, 데이터의 흐름을 결정하는 스레드observeOn()발행된 데이터를 가공하고, 구독해서 처리하는 것을 담당하는 스레드- 데이터를 발행 > 데이터 가공 > 데이터 구독
리액티브 프로그래밍을 통해 발생하는 비동기적인 데이터의 흐름을 시각의 흐름에 따라 시각적으로 표시한 다이어그램
- 문장으로 적혀 있는 리액티브 연산자의 기능을 이해하기 어려움
- 리액티브 연산자의 기능이 시각화되어 있어서 이해하기 쉬움
- 리액티브 프로그래밍의 핵심 연산자를 사용하기 위한 핵심 도구
- 리액티브 프로그래밍 라이브러리의 표준 사양이다
- RxJava는 Reactive Streams의 인터페이스들을 구현한 구현체이다.
- Reactive Streams는 Publisher, Subscriber, Subscription, Processor라는 4개의 인터페이스를 제공한다.
- Publisher: 데이터를 생성하고 통지한다.
- Subscriber: 통지된 데이터를 전달받아서 처리한다.
- Subscription: 전달받을 데이터의 개수를 요청
Publisher <-- Subscriber: 데이터를 구독한다. Subscribe
Publisher --> Subscriber: 데이터를 통지할 준비가 되었음을 알린다. OnSubscribe
Publisher <-- Subscriber: 전달 받은 통지 데이터 개수를 요청한다. Subscription.request
Publisher --> Publisher: 데이터를 생성한다.
Publisher --> Subscriber: 요청 받은 개수만큼 데이터를 총지한다. OnNext
Publisher --> Publisher: 데이터를 생성한다.
Publisher --> Publisher: 데이터를 생성한다.
Publisher <-- Subscriber: 전달 받을 통지 데이터 개수를 요청한다. Subscription.request
Publisher --> Subscriber: 요청 받은 개수만큼 데이터를 통지한다. OnNext
Publisher --> Subscriber: 데이터 통지가 완료 되었음을 알린다. OnComplete
- 생산자는 소비자가 구독할 때마다 데이터를 처음부터 새로 통지한다.
- 데이터를 통지하는 새로운 타임 라인이 생성된다.
- 소비자는 구독 시점과 상관없이 통지된 데이터를 처음부터 전달받을 수 있다.
- Flowable, Observable이 대표적인 Cold Publisher
@Test
void Cold_Publisher_Example() {
Flowable<Integer> flowable = Flowable.just(1, 3, 4, 7);
flowable.subscribe(data -> System.out.println("구독자1: " + data));
flowable.subscribe(data -> System.out.println("구독자2: " + data));
}
// 구독자1: 1
// 구독자1: 3
// 구독자1: 4
// 구독자1: 7
// 구독자2: 1
// 구독자2: 3
// 구독자2: 4
// 구독자2: 7- 구독 순서와 상관 없이
@Test
fun `콜드 옵저버블`() {
val observable = listOf("string1", "string2", "string3", "string4").toObservable()
observable.subscribe(
{
println("Received $it")
},
{
println("Error ${it.message}")
},
{
println("Done")
}
)
observable.subscribe(
{
println("Received $it")
},
{
println("Error ${it.message}")
},
{
println("Done")
}
)
//Received string1
//Received string2
//Received string3
//Received string4
//Done
//Received string1
//Received string2
//Received string3
//Received string4
//Done
}동일한 옵저버블을 여러 번 구독해도 모든 구독의 새로운 배출을 얻을 수 있다. 옵저버블은 특징적인 기능을 갖고 있는데 각 구독마다 처음부터 아이템을 배출하는 것을 콜드 옵저버블이라고 한다. 구체적으로 설명하면 콜드 옵저블은 구독 시에 실행을 시작하고 subscribe가 호출되면 아이템을 푸시 하기 시작하는데 각 구독에서 아이템의 동일한 순서를 푸시 한다.

- 생상자는 소비자 수와 상관없이 데이터를 한 번만 통지한다
- 즉, 데이터를 통지하는 타임 라인은 하나이다.
- 소비자는 발행된 데이터를 처음부터 전달받은 게 아니라 구독한 시점에 통지된 데이터들만 전달받을 수 있다.
@Test
void Hot_Publisher_Example() {
PublishProcessor<Integer> processor = PublishProcessor.create();
processor.subscribe(data -> System.out.println("구독자1: " + data));
processor.onNext(1);
processor.onNext(3);
processor.subscribe(data -> System.out.println("구독자2: " + data));
processor.onNext(4);
processor.onNext(7);
processor.onComplete();
// 구독자1: 1
// 구독자1: 3
// 구독자1: 4
// 구독자2: 4
// 구독자1: 7
// 구독자2: 7
}콜드 옵저블은 수동적이며 구독이 호출될 때까지 아무것도 보내지 않는다. 핫 옵저버블은 콜드 옵저버블과 반대로, 배출을 시작하기 위해 구독할 필요가 없다. 콜드 옵저버블을 CD/DVD 레코딩으로 본다면 핫 옵저버블은 TV 채널과 비슷하다. 핫 옵저버블은 시청자가의 시청 여부에 관계없이 콘텐츠를 계속 브로드캐스팅 한다. 핫 옵저저블은 데이터보다는 이벤트와 유사하다.
@Test
fun `핫 옵저버블`() {
val connectableObservable = listOf("string1", "string2", "string3", "string4", "string5").toObservable().publish()
connectableObservable.subscribe { println("Subscription 1: $it") } // 콜드 옵저버블
connectableObservable.map(String::reversed).subscribe { println("Subscription 2: $it") } // 콜드 옵저버블
connectableObservable.connect() // connect를 사용하여 콜드 옵저저블을 핫 옵저저블로 변경한다.
connectableObservable.subscribe { println("Subscription 3: $it") }
}@Test
fun `핫 옵저버블2`() {
val connectableObservable = Observable.interval(100, TimeUnit.MILLISECONDS).publish()
connectableObservable.subscribe { println("Subscription 1: $it") } // 콜드 옵저버블
connectableObservable.subscribe { println("Subscription 2: $it") }
connectableObservable.connect() // connect를 사용하여 콜드 옵저저블을 핫 옵저저블로 변경한다.
runBlocking { delay(500) }
connectableObservable.subscribe { println("Subscription 3: $it") }
runBlocking { delay(500) }
//Subscription 1: 0
//Subscription 2: 0
//Subscription 1: 1
//Subscription 2: 1
//Subscription 1: 2
//Subscription 2: 2
//Subscription 1: 3
//Subscription 2: 3
//Subscription 1: 4
//Subscription 2: 4
//Subscription 1: 5
//Subscription 2: 5
//Subscription 3: 5
//Subscription 1: 6
//Subscription 2: 6
//Subscription 3: 6
//Subscription 1: 7
//Subscription 2: 7
//Subscription 3: 7
//Subscription 1: 8
//Subscription 2: 8
//Subscription 3: 8
//Subscription 1: 9
//Subscription 2: 9
//Subscription 3: 9
}세 번째 구독이 5번째 배출을 받았고 이전의 구독을 모두 놓쳤다는 것을 확인 할 수있다.
| Flowable | Observable |
|---|---|
| Reactive Streams 인터페이스를 구현함 | Reactive Streams 인터페이스를 구현하지 않음 |
| Subscriber에서 데이터를 처리한다. | Observer에서 데이터를 처리한다. |
| 데이터 개수를 제어하는 배압이 가능이 있음 | 데이터 개수를 제어하는 배압이 기능이 없음 |
| Subscription으로 전달 받은 데이터 개수를 제어할 수 있다. | 배압 기능이 없기 때문에 데이터 개수를 제어할 수 없다. |
| Subscription으로 구독을 해지한다. | Disposable로 구독을해지한다 |
플로어블은 옵저버들의 백프레셔 버전이라고 부를 수 있다. 아마 두 가지 유일한 차이점은 플오어블이 백프레셔를 고려한다는 점뿐인데 옵저버들은 가능하지 않다. 그게 전부다. 플로어블은 연산자를 위해 최대 128개의 항목을 가질 수 있는 버퍼를 제공한다. 그래서 컨슈머가 시간이 걸리는 작업을 실행할 때 배출된 항목이 버퍼에 대기할 수 있다.
@Test
fun `풀로어블`() {
Observable.range(1, 1000) //(1)
.map { MyItem(it) } //(2)
.observeOn(Schedulers.computation())
.subscribe( //(3)
{
println("Received $it")
runBlocking { delay(50) } //(4)
},
{
it.printStackTrace() //(5)
}
)
runBlocking { delay(6000) }
}
data class MyItem(val id: Int) {
init {
println("MyItem Created $id")
}
}- Observable.range() 연산자를 사용해서 1에서 1000 사이의 숫자를 배출하는 간단한 코드이다.
- (2) map 연산자로 Int에서 MyItem3 객체를 생성한다.
- (3) 옵저버블을 구독했다.
- (4) 시간이 오래 걸리는 구독 코드를 흉내 내기 위해 지연 연산을 실행
- (5) 다시 프로그램이 실행을 멈추기 전에 컨슈머가 모든 아이템의 처리를 기다리는 블로킹 코드
MyItem Created 1
MyItem Created 5
Recived MyItem(id=1)
MyItem Created 6
...
MyItem Created 1000
Recived MyItem(id=2)
...
Recived MyItem(id=113)
Recived MyItem(id=114)
옵저버는 그것과 보조를 맞추지 않는다. 옵저저블이 모든 항목을 배출할 동안 옵저버는 첫 번째 항목만을 처리했다. 앞에서 설명한 것처럼 이런 현상은 OutOfMemory 오류를 비롯해 많은 문제를 발생 시킬 수 있다. Flowable로 변경해 보자
@Test
fun `flowable`() {
Flowable.range(1, 1000)
.map { MyItem(it) }
.observeOn(Schedulers.io())
.subscribe(
{
println("Receivbed $it")
runBlocking { delay(50) }
},
{
it.printStackTrace()
}
)
runBlocking { delay(6000) }
}MyItem Created 1
MyItem Created 4
Receivbed MyItem(id=1)
MyItem Created 6
..
MyItem Created 128
Receivbed MyItem(id=2)
...
Receivbed MyItem(id=94)
Receivbed MyItem(id=95)
Receivbed MyItem(id=96)
MyItem Created 129
MyItem Created 130
...
MyItem Created 220
MyItem Created 221
MyItem Created 222
MyItem Created 223
MyItem Created 224
Receivbed MyItem(id=97)
...
Receivbed MyItem(id=113)
Receivbed MyItem(id=114)
플로어블은 모든 아이템을 한 번에 배출하지 않고 컨슈머가 처리를 시작할 수 있을 때까지 기다렸다가 다시 배출을 전달하며, 완료될 때까지 이 동작을 반복한다.
리액티브 프로그래밍에서 옵저버블은 그 컨슈머가 소비할 수 있는 값을 산출해 내는 기본 계산 작업을 갖고 있다. 여기서 중요한 것은 컨슈머가 값을 풀 방식으로 접근하지 않는다는 점이다. 오히려 옵저버블은 컨슈머에게 값을 푸쉬하는 역할을 한다. 따라서 옵저버블은 인련의 연산자를 거친 아이템을 최종 옵저버로 보내는 푸시 기반의 조합 가능한 이터레이터다.
- 옵저버는 옵저버블을 구독한다.
- 옵저버블이 그 내부의 아이템들을 내보내기 시작한다.
- 옵저버는 옵저버블에서 내보내는 모든 아이템에 반응 한다.
- onNext: 옵저버블은 모든 아이템을 하나씩 이 메서드에 전달한다.
- onComplete: 모든 아이템이 onNext 메서드를 통과하면 옵저버블은 onComplete 메서드를 호출한다.
- onError: 옵저버블에서 에러가 발생하면 onError 메서드가 호출돼 정의된 대로 에러를 처리한다. onError와 onComplete는 터미널 이벤트다. onError가 호출 돼었을 경우 onComplete 가 호출되지 않으며, 반대의 경우도 마찬가지이다.
@Test
internal fun `observer`() {
val observer: Observer<Any> = object : Observer<Any> {
override fun onComplete() {
println("onComplete")
}
override fun onSubscribe(d: Disposable) {
println("onSubscribe: $d")
}
override fun onError(e: Throwable) {
println("onError: $e")
}
override fun onNext(item: Any) {
println("onNext: $item")
}
}
val observable: Observable<Any> = listOf("One", 2, "Three", "Four", 4.5, "Five", 6.0f).toObservable() //6
observable.subscribe(observer)//7
val observableOnList: Observable<List<Any>> = Observable.just(
listOf("One", 2, "Three", "Four", 4.5, "Five", 6.0f),
listOf("List with Single Item"),
listOf(1, 2, 3, 4, 5, 6)
)//8
observableOnList.subscribe(observer)//9
}- observer 인터페이스는 4개의 메서드가 선언돼 있다.
- onComplete() 메서드는 Observable이 오류 없이 모든 아이템을 처리하면 호출된다.
- onNext() 메서드는 옵저버블이 내보내는 각 아이템에 대해 호출된다.
- onError() 메서드는 옵저버블이 오류가 발생했을 때 호출된다.
- onSubscribe() 메서드는 옵저버가 옵저버블을 구독할 때 마다 호출된다 .
지금쯤 플로어블을 사용하기 편리한 도구라고 생각하고 모든 옵저버블은 대체할 수도 있다. 그러나 항상 플로어블이 옵저버블보다 나은 것은아니다. 플로어블은 백프레셔 전략을 제공하지만 옵저버블이 존재하는 데는 이유가 있으며 둘 다 장단점이 있다.
다음은 플로어블의 사용을 고려해야 할 상항이다. 플로어블은 옵저버블보다 느리다는 것을 기억하자.
- 플로어블과 백프레셔는 더 많은 양의 데이터를 처리할 때 도움이 된다. 따라서 원천 데이터 10,000개 이상의 아이템을 배출한다면 플로어블을 사용하자. 특히 원천이 비동기적으로 동작해 필요시에 컨슈머 체인이 생상자에게 배출량을 제한/규제을 요청할 수 있는 경우에 접합하다.
- 파일이나 데이터베이스를 읽거나 파싱하는 경우다.
- 결과를 반환하는 동안 IO 소스의 양을 조절할 수 있는 블로킹을 지원하는 네티워크 IO 작업/스프리밍 API에서 배출할 때 사용한다.
- 소량의 데이터(10,000개 미만의 배출)를 다룰 때
- 오로지 동기 방식으로 작업하길 원하거나 또는 제한된 동시성을 가진 작업을 수행할 때
- UI 이벤트를 발생 시킬 때
플로어블은 옵저버 대신 백프레셔 호환이 가능한 구독자를 사용한다. 그러나 람다식을 사용한다면 차이점을 발견 할 수 없을 것이다. 그렇다면 옵저버 대신 구독자를 사용해야 하는 이유는 무엇일까? 왜냐하면 구독자가 일부 추가 기능과 빽프레셔를 동시에 지원하기 때문이다. 예를 들어 얼마나 많은 아이템을 받기를 원하는지 메시지로 전당할 수 있다. 아니면 구독자를 사용하는 동안 업스트림에서 수신하고자 하는 항목의 수를 지정하도록 할 수 있는데 아무값도 지정하지 안흥면 어떤 배출도 수신하리 못할 것이다.
코드에서 원하는 배출량을 지정하지 않았지만 내부적으로 배출량을 무제한으로 요청했기 때문에 배출된 모든 아이템을 수신할 수 있었다.
@Test
fun subscriber() {
Flowable.range(1, 15)
.map { MyItem(it) }
.observeOn(Schedulers.io())
.subscribe(object : Subscriber<MyItem> {
lateinit var subscription: Subscription
override fun onSubscribe(subscription: Subscription) {
this.subscription = subscription
subscription.request(5)
}
override fun onNext(t: MyItem?) {
runBlocking { delay(50) }
println("Subscriber received $t")
if (t!!.id == 5) {
println("Request two more")
subscription.request(2)
}
}
override fun onError(t: Throwable) = t.printStackTrace()
override fun onComplete() = println("Done")
})
runBlocking { delay(10000) }
}
MyItem Created 1
MyItem Created 2
...
MyItem Created 15
Subscriber received MyItem(id=1)
Subscriber received MyItem(id=2)
Subscriber received MyItem(id=3)
Subscriber received MyItem(id=4)
Subscriber received MyItem(id=5)
Request two more
Subscriber received MyItem(id=6)
Subscriber received MyItem(id=7)
BUILD SUCCESSFUL in 13s
subscription의 구독을 초기에는 5로 서정했고 5게 이상 부터는 2개식 구독을 진행하는 것으로 수정했다. 걀과를 보면 해당 설정을 이해할 수 있다.

Flowable에서 데이터를 통지하는 속도가 Subscriber에서 통지된 데이터를 전달받아 처리하는 속도 보다 빠를 때 밸런스를 맞추기 위해 데이터 통지량을 제어하는 기능을 말한다.
@Test
void missing_back_pressure() throws InterruptedException {
Flowable.interval(1L, TimeUnit.MILLISECONDS)
.doOnNext(data -> Logger.log(LogType.DO_ON_NEXT, data))
.observeOn(Schedulers.computation())
.subscribe(
data -> {
Logger.log(LogType.PRINT, "# 소비자 처리 대기 중..");
TimeUtil.sleep(1000L);
Logger.log(LogType.ON_NEXT, data);
},
error -> Logger.log(LogType.ON_ERROR, error),
() -> Logger.log(LogType.ON_COMPLETE)
);
Thread.sleep(2000L);
}
doOnNext() | RxComputationThreadPool-2 | 00:24:14.790 | 0
doOnNext() | RxComputationThreadPool-2 | 00:24:14.794 | 1
doOnNext() | RxComputationThreadPool-2 | 00:24:14.795 | 2
print() | RxComputationThreadPool-1 | 00:24:14.794 | # 소비자 처리 대기 중..
...
onNext() | RxComputationThreadPool-1 | 00:24:15.796 | 0
onERROR() | RxComputationThreadPool-1 | 00:24:15.796 | io.reactivex.exceptions.MissingBackpressureException: Can't deliver value 128 due to lack of requestsdoOnNext()는 interval()에서 통지하는 데이터를 처리하는 Callback 함수
생산자 쪽에서 통지한 첫 번째 데이터만 처리 onNext() | RxComputationThreadPool-1 | 00:24:15.796 | 0 하고 onERROR() | RxComputationThreadPool-1 | 00:24:15.796 | io.reactivex.exceptions.MissingBackpressureException: Can't deliver value 128 due to lack of requests예외가 발생, 생사자 쪽에서 통지하는 속도가 소비자에서 처리하는 속도 보다 빠르기 때문에 예외가 발생한다. 이러한 불균형을 처리하기 위해서 배압전략을 지원한다
옵저저블의 유일한 문제 상황은 옵저버가 옵저저블 속도에 대처할 수 없는 경우다. 옵저저블은 기본적으로 아이템을 동기적으로 옵저버에 하나씩 푸시해 동작한다. 그러나 옵저버가 시간을 필요로 하는 작업을 처리해야 한다면 그 시간이 옵저저블이 각 항목을 배출하는 간격보다 길어질수 있다.
@Test
fun `백프레셔 이해`() {
val observable = Observable.just(1, 2, 3, 4, 5, 6, 7, 9) // (1)
val subject = BehaviorSubject.create<Int>()
subject.observeOn(Schedulers.computation()) // (2)
.subscribe {
println("Sub 1 Received $it")
runBlocking { delay(200) } // (4)
}
subject.observeOn(Schedulers.computation()) // (5)
.subscribe {// (6)
println("Sub 2 Received $it")
}
observable.subscribe(subject) // (7)
runBlocking { delay(200) } // (8)
}- (1): 옵저저블을 생성한다
- (2),(3): 구독한다
- (7): BehaviorSubject를 구독한 후에 BehaviorSubject를 사용해 옵저저블을 구독하면 BehaviorSubject의 모든 배출을 받을 수 있게 된다.
- (4): 첫 번쨰 구독 내에서 시간이 오래 걸리게 하기 위해서 delay 메서드를 사용한다
subject.observeOn(Schedulers.computation())메서드는observeOn에서 구독을 실행하는 스레드를 지정하도록 해주고Schedulers.computation()은 계산을 수행할 스레드를 제공한다.- (8): 실행은 백그라운드(다른 스레드)에서 수행하기 때문에 코드를 확인 하기 위해서 delay를 진행
Sub 2 Received 1
Sub 1 Received 1
Sub 2 Received 2
Sub 2 Received 3
Sub 2 Received 4
Sub 2 Received 5
Sub 2 Received 6
Sub 2 Received 7
Sub 2 Received 9
Sub 1 Received 2
해당 출력은 구독을 번갈아가면서 1~9 까지 모든 순자를 출력하지 않는다. 이 프로그램은 두 옵저버에 한 번만 배출하는 subject인 핫 옵저버블로서의 행동을 멈춘것은 아니다. 그러나 첫 번쨰 옵저버에서 각 계산이 오래 걸렸기 때문에 각 배출들은 대기열로 들어가게 된것이다. 이것은 OutOfMemoryError 예뢰를 포함해 많은 문제를 일으킬 수 있으므로 좋지 않은 행동이다.
@Test
fun `백프레셔 이해 2`() {
val observable = Observable.just(1, 2, 3, 4, 5, 6, 7, 9) // (1)
observable
.map { MyItem(it) } // (2)
.observeOn(Schedulers.computation()) // (3)
.subscribe { // (4)
println("Received $it")
runBlocking { delay(200) } // (5)
}
runBlocking { delay(2000) } // (6)
}
data class MyItem(val id: Int) {
init {
println("MyItem Created $id") // (7)
}
}(2)에서 사용한 map 연산자를 사용해 Int 항목을 MyItem 객체로 변환했다. 예제에서 map은 배출 아이템을 추적하는데 사용 했다. 배출이 발생할 때 마다 즉시 map 연산자로 전달돼 MyItem 클래스의 객체를 생성한다.
MyItem Created 1
MyItem Created 2
MyItem Created 3
MyItem Created 4
MyItem Created 5
MyItem Created 6
Received MyItem(id=1)
MyItem Created 7
MyItem Created 9
Received MyItem(id=2)
Received MyItem(id=3)
Received MyItem(id=4)
Received MyItem(id=5)
Received MyItem(id=6)
Received MyItem(id=7)
Received MyItem(id=9)
배출의 출력에서 볼 수 있듯이 MyItem의 생성은 매우 빠르며 컨슈머로 알려진 옵저버가 인쇄를 시작도 하기 전에 완료되었다. 여기서 볼 수 있듯이 문제는 배출이 대기열에 쌓이고 있는데 컨슈머는 이 전의 배출량을 처리하고 있다는 것이다.
RxJava에서는 BackpressureStrategy를 통해서 Flowable이 통지 대기 중 데이터를 어떻게 다룰지에 대한 배압 전략을 제공한다.
- 배압을 적용하지 않는다.
- 나중에
OnBackpressureXXX()로 배압 적용을 할 수 있다.
- 통지된 데이터가 버퍼의 크기를 초과하면
MissingBackpressureException에러를 통지한다. - 즉, 소비자가 생산자의 ㅗㅇ지 속도를 따라 잡지 못할 때 발생한다.

- 버퍼가 가득 찬 시점에 가장 먼저 Drop이 된 데이터를 기억해두었다가 버퍼를 비우게되면 기억해둔 데이터부터 버퍼에 담는다.
10까지 버퍼에 들어간 경우11부터 데이터를drop하게된다. 이후 해당 버퍼가 모두 비워지면11부터(drop된 순서 부터) 차례대로 진행된다.
@Test
void back_pressure_drop() {
Flowable.interval(1L, TimeUnit.MILLISECONDS)
.onBackpressureBuffer(
128,
() -> Logger.log(LogType.PRINT, "# Overflow 발생!"),
BackpressureOverflowStrategy.DROP_LATEST
)
.doOnNext(data -> Logger.log(LogType.DO_ON_NEXT, data))
.observeOn(Schedulers.computation())
.subscribe(
data -> {
TimeUtil.sleep(5L);
Logger.log(LogType.ON_NEXT, data);
},
error -> Logger.log(LogType.ON_ERROR, error)
);
TimeUtil.sleep(1000L);
}- 생산자 쪽에서는
interval()를 통해서1 MILLISECONDS주기로 0 부터 숫자를 차례대로 빠르게 통지함 onBackpressureBuffer()128버퍼의 사이즈를 의미, Default value 128- 버퍼가 가득 찼을때 호출되는 Callback 함수
- 버퍼가 가득 찼을때 사용할 전략
subscribe()- 구독하는 소비자 쪽에서는
5 MILLISECONDS대기 시간을 갖으면서, 생산자 쪽에서 전달받은 데이터를 처리를 진행한다. - 속도의 차이가 있기 때문에 배압 전략이 필요하다
- 구독하는 소비자 쪽에서는
doOnNext() | RxComputationThreadPool-2 | 00:43:25.340 | 0
doOnNext() | RxComputationThreadPool-2 | 00:43:25.343 | 1
doOnNext() | RxComputationThreadPool-2 | 00:43:25.343 | 2
...
onNext() | RxComputationThreadPool-1 | 00:43:25.348 | 0
...
onNext() | RxComputationThreadPool-1 | 00:43:25.585 | 40
print() | RxComputationThreadPool-2 | 00:43:25.586 | # Overflow 발생!
print() | RxComputationThreadPool-2 | 00:43:25.587 | # Overflow 발생!
...
onNext() | RxComputationThreadPool-1 | 00:43:25.898 | 95
doOnNext() | RxComputationThreadPool-1 | 00:43:25.898 | 128
- 생산하는 쪽의 속도가 구독하는 쪽의 속도보다 훨씬 빠름,
doOnNext()은 여러번 호출되지만,onNext()는 호출 횟수가 낮음 - 버퍼가 가득 차는 시점에
# Overflow 발생!이 발생, buffe size는128이지만, 버퍼가 비워지는 실제 사이지는95 95까지 구독 처리를 완료한 이후 버퍼가 지워짐,buffer size 128이기 때문에 가장 먼저 drop된128부 buffer에 채워지게 된다.

- 버퍼가 가득 찬 시점에서 가장 마지막에 Drop된 데이터를 기억해두었다가 버퍼를 비우게되면 기억해둔 데이터부터 버퍼에 담는다.
1 ~ 10버퍼 크기가 가득 찼다면, 통지된 데이터들은 뒤에 쌓이게 된다.- 버퍼가 비워질때 까지 기다리다가 버퍼가 비워지면 가장 마지막에 Drop된
14번부터 차례대로 버퍼에 담긴다. 11 ~ 13까지 데이터의 손실이 생긴다.
@Test
void back_pressure_drop_oldest() {
Flowable.interval(1L, TimeUnit.MILLISECONDS)
.onBackpressureBuffer(
128,
() -> Logger.log(LogType.PRINT, "# Overflow 발생!"),
BackpressureOverflowStrategy.DROP_OLDEST
)
.doOnNext(data -> Logger.log(LogType.DO_ON_NEXT, data))
.observeOn(Schedulers.computation())
.subscribe(
data -> {
TimeUtil.sleep(5L);
Logger.log(LogType.ON_NEXT, data);
},
error -> Logger.log(LogType.ON_ERROR, error)
);
TimeUtil.sleep(1000L);
}- 생산자 쪽에서는
interval()를 통해서1 MILLISECONDS주기로 0 부터 숫자를 차례대로 빠르게 통지함 onBackpressureBuffer()를 통해서DROP_OLDEST전략을 지정, Orverflow가 발생했을 경우 처리할 Callback 메서드 지정doOnNext()생산자 쪽에서 통지한 데이터를 그대로 출력subscribe생상자 쪽에서 통지한 데이터를 구독해서 처리함
doOnNext() | RxComputationThreadPool-2 | 01:17:56.609 | 0
doOnNext() | RxComputationThreadPool-2 | 01:17:56.612 | 1
doOnNext() | RxComputationThreadPool-2 | 01:17:56.612 | 2
...
onNext() | RxComputationThreadPool-1 | 01:17:56.618 | 0
...
doOnNext() | RxComputationThreadPool-2 | 01:17:56.724 | 127
...
print() | RxComputationThreadPool-2 | 01:17:56.853 | # Overflow 발생!
...
onNext() | RxComputationThreadPool-1 | 01:17:57.152 | 95
doOnNext() | RxComputationThreadPool-1 | 01:17:57.152 | 428
doOnNext() | RxComputationThreadPool-1 | 01:17:57.152 | 429
doOnNext() | RxComputationThreadPool-1 | 01:17:57.152 | 430
...
- 통지한 데이터를 출력
- 버퍼 사이즈를 128으로 지정했기 때문에
0 ~ 127까지 버퍼에 채워짐 128부터 Overflow가 계속 발95까지 데이터를 통지한 데이터를 구독해서 처리Drop Oldest전략이기 때문에 가장 마지막에 발생한Overflow 발생!이후 통지한 데이터428부터 차례대로 버퍼에 쌓기 시작함127 ~ 427통지한 데이터는 유실이 발생

- 버퍼에 데이터가 모두 채워진 상태가 되면 이후에 생성되는 데이터를 버리고(Drop), 버퍼가 비워지는 시점에 Drop되지 않은 데이터 부터 다시 버퍼에 담는다.
1 ~ 10버퍼 크기가 가득 찼다면, 통지된 데이터들은 뒤에 쌓이게 된다.- 버퍼가 비워질때 까지 기다리다가 버퍼가 비워지면 Drop이 데이터는 모두 버리 Drop이 되지 않은 데이터 부터 버퍼에 채운다.
Drop Oldest같은 경우 마지막에 Drop된 데이터14부터 들어가게 되기 때문에 차이가 있다.
@Test
void back_pressure_drop() {
Flowable.interval(1L, TimeUnit.MILLISECONDS)
.onBackpressureDrop(dropData -> Logger.log(LogType.PRINT, "오버플로우 발생! - " + dropData + " Drop!"))
.doOnNext(data -> Logger.log(LogType.ON_NEXT, data))
.observeOn(Schedulers.computation())
.subscribe(
data -> {
TimeUtil.sleep(5L);
Logger.log(LogType.ON_NEXT, data);
}
);
TimeUtil.sleep(1000L);
}onNext() | RxComputationThreadPool-2 | 01:44:50.547 | 0
onNext() | RxComputationThreadPool-2 | 01:44:50.550 | 1
onNext() | RxComputationThreadPool-2 | 01:44:50.550 | 2
...
onNext() | RxComputationThreadPool-1 | 01:44:50.556 | 0
...
onNext() | RxComputationThreadPool-2 | 01:44:50.662 | 127
print() | RxComputationThreadPool-2 | 01:44:50.664 | 오버플로우 발생! - 128 Drop!
...
onNext() | RxComputationThreadPool-1 | 01:44:51.095 | 95
onNext() | RxComputationThreadPool-2 | 01:44:51.095 | 560
onNext() | RxComputationThreadPool-2 | 01:44:51.097 | 561
...
- 통지한 데이터를 출력
- 버퍼 사이즈를 128으로 지정했기 때문에
0 ~ 127까지 버퍼에 채워짐 128부터 Overflow가 계속 발생95까지 데이터를 통지한 데이터를 구독해서 처리Drop전략이기 때문에 Drop된 데이터는 제거 이후 통지된 데이터540부터 버퍼에 차례대로 쌓기 시작함

- 버퍼에 데이터가 모두 채워진 상태가 되면 버퍼가 비워질 때 까지 통지된 데이터는 버퍼 밖에서 대기하며 버퍼가 비워지는 시점에 가장 가장 최근 통지된 데이터 부터 버퍼에 담는다.
1 ~ 10버퍼가 가득찼다면, 가장 나중에 통지된20데이터 부터 버퍼 채워지게 된다.
@Test
void back_pressure_latest() {
Flowable.interval(1L, TimeUnit.MILLISECONDS)
.onBackpressureLatest()
.doOnNext(data -> Logger.log(LogType.DO_ON_NEXT, data))
.observeOn(Schedulers.computation())
.subscribe(
data -> {
TimeUtil.sleep(5L);
Logger.log(LogType.ON_NEXT, data);
},
error -> Logger.log(LogType.ON_ERROR, error)
);
TimeUtil.sleep(1000L);
}doOnNext() | RxComputationThreadPool-2 | 01:55:33.720 | 0
doOnNext() | RxComputationThreadPool-2 | 01:55:33.724 | 1
...
onNext() | RxComputationThreadPool-1 | 01:55:33.729 | 0
...
doOnNext() | RxComputationThreadPool-2 | 01:55:33.836 | 127
...
onNext() | RxComputationThreadPool-1 | 01:55:34.288 | 95
doOnNext() | RxComputationThreadPool-1 | 01:55:34.288 | 579
...
127까지 통지하게 되면 버퍼가 가득차게됨- 소비자 측에서는
95까지 전달 받은 데이터를 처리 하고 버퍼가 지워지게 - 버퍼가 지워지는 시점에 가장 마지막에 통지된 데이터가
579이기 때문에 처리
@Test
void flow_able_example() throws InterruptedException {
Flowable<String> flowable = Flowable.create(
new FlowableOnSubscribe<String>() {
@Override
public void subscribe(FlowableEmitter<String> emitter) throws Exception {
String[] datas = {"Hello", "RxJava"};
for (final String data : datas) {
// 구독이 해지되면 처리 중단
if (emitter.isCancelled()) {
return;
}
// 데이터 통지
emitter.onNext(data);
}
emitter.onComplete();
}
},
BackpressureStrategy.BUFFER
);
flowable.observeOn(Schedulers.computation())
.subscribe(new Subscriber<String>() {
// 데이터 개수 요청 및 구독을 취소하기 위한 객체
private Subscription subscription;
@Override
public void onSubscribe(Subscription subscription) {
this.subscription = subscription;
this.subscription.request(Long.MAX_VALUE);
}
@Override
public void onNext(String data) {
Logger.log(LogType.ON_NEXT, data);
}
@Override
public void onError(Throwable error) {
Logger.log(LogType.ON_ERROR);
}
@Override
public void onComplete() {
Logger.log(LogType.ON_COMPLETE);
}
});
}- 첫 번째 파라미터는
FlowableOnSubscribe의 익명 클래스로(함수형 인터페이스)을 람다형식으로 작성void subscribe(@NonNull FlowableEmitter<T> emitter)메서드를 구현FlowableEmitter가 실제적으러 데이터를 통제하는 역항을 진행한다.
- 두 번째
Flowable배얍을 지원하기 때문에 배압 전략을 전달 받는다.
subscribe()메서드를 통해 데이터를 구독한다. 구독하게 되면 생산자쪽에서 데이터 통지할 준비가 되었음을 알려주기 위해 생산자 쪽에 요청을 하게된다. 이때 생산자 쪽에void subscribe(@NonNull FlowableEmitter<T> emitter)메서드가 호출된다.- 생산자의
subscribe메서드에서는 데이터를 통지 할때emitter.onNext(data);메서드를 사용한다. 이때 소비자의subscribe메서드의onNext메서드가 호출된다.
- 생산자의
- 데이터를 모두 발행하게 되면
emitter.onComplete();메서드를 통해 데이터 발행 완료를 알린다. 이 때onComplete메서드를 호출한다.
@Test
void observable_example() throws InterruptedException {
Observable<String> observable = Observable.create(
new ObservableOnSubscribe<String>() {
@Override
public void subscribe(ObservableEmitter<String> emitter) throws Exception {
String[] datas = {"Hello", "RxJava"};
for (final String data : datas) {
// 구독 해지가 돠면 처리 중단
if (emitter.isDisposed()) {
return;
}
emitter.onNext(data);
}
emitter.onComplete();
}
}
);
observable.observeOn(Schedulers.computation())
.subscribe(new Observer<String>() {
@Override
public void onSubscribe(Disposable d) {
// 배압 기능이 없기 때문에 이무것도 처리하지 않음
}
@Override
public void onNext(String data) {
Logger.log(LogType.ON_NEXT, data);
}
@Override
public void onError(Throwable error) {
Logger.log(LogType.ON_ERROR, error);
}
@Override
public void onComplete() {
Logger.log(LogType.ON_COMPLETE);
}
});
Thread.sleep(500L);
}- subscribe 메서드를 통해서 데이터를 통제함
- onSubscribe 배압 기능이 없기 때문에 아무것도 처리하지 않음
- subscribe 메서드가 호출하게되면 생산자 onNext 메서드가 호출됨
- 데이터를 1건만 통지하거나 에러를 통지한다.
- 데이터 통지 자체가 완료를 의미하기 때문에 완료 통지는 하지 않는다.
- 데이터 1건만 통지하므로 데이터개수를 요청할 필요가 없다.
onNext(),onComplete()가 없으며 이 둘을 합한onSuccess()를 제공한다.Single의 대표적인 소비자는SingleObserver이다.- 클라이언트 요청에 대응하는 서버의 응답이
Single을 사용하기 좋은 대표적인 예다
지금쯤 플로어블을 사용하기 편리한 도구라고 생각하고 모든 옵저버블은 대체할 수도 있다. 그러나 항상 플로어블이 옵저버블보다 나은 것은아니다. 플로어블은 백프레셔 전략을 제공하지만 옵저버블이 존재하는 데는 이유가 있으며 둘 다 장단점이 있다.
다음은 플로어블의 사용을 고려해야 할 상항이다. 플로어블은 옵저버블보다 느리다는 것을 기억하자.
- 플로어블과 백프레셔는 더 많은 양의 데이터를 처리할 때 도움이 된다. 따라서 원천 데이터 10,000개 이상의 아이템을 배출한다면 플로어블을 사용하자. 특히 원천이 비동기적으로 동작해 필요시에 컨슈머 체인이 생상자에게 배출량을 제한/규제을 요청할 수 있는 경우에 접합하다.
- 파일이나 데이터베이스를 읽거나 파싱하는 경우다.
- 결과를 반환하는 동안 IO 소스의 양을 조절할 수 있는 블로킹을 지원하는 네티워크 IO 작업/스프리밍 API에서 배출할 때 사용한다.
- 소량의 데이터(10,000개 미만의 배출)를 다룰 때
- 오로지 동기 방식으로 작업하길 원하거나 또는 제한된 동시성을 가진 작업을 수행할 때
- UI 이벤트를 발생 시킬 때
플로어블은 옵저버 대신 백프레셔 호환이 가능한 구독자를 사용한다. 그러나 람다식을 사용한다면 차이점을 발견 할 수 없을 것이다. 그렇다면 옵저버 대신 구독자를 사용해야 하는 이유는 무엇일까? 왜냐하면 구독자가 일부 추가 기능과 빽프레셔를 동시에 지원하기 때문이다. 예를 들어 얼마나 많은 아이템을 받기를 원하는지 메시지로 전당할 수 있다. 아니면 구독자를 사용하는 동안 업스트림에서 수신하고자 하는 항목의 수를 지정하도록 할 수 있는데 아무값도 지정하지 안흥면 어떤 배출도 수신하리 못할 것이다.
코드에서 원하는 배출량을 지정하지 않았지만 내부적으로 배출량을 무제한으로 요청했기 때문에 배출된 모든 아이템을 수신할 수 있었다.
@Test
fun subscriber() {
Flowable.range(1, 15)
.map { MyItem(it) }
.observeOn(Schedulers.io())
.subscribe(object : Subscriber<MyItem> {
lateinit var subscription: Subscription
override fun onSubscribe(subscription: Subscription) {
this.subscription = subscription
subscription.request(5)
}
override fun onNext(t: MyItem?) {
runBlocking { delay(50) }
println("Subscriber received $t")
if (t!!.id == 5) {
println("Request two more")
subscription.request(2)
}
}
override fun onError(t: Throwable) = t.printStackTrace()
override fun onComplete() = println("Done")
})
runBlocking { delay(10000) }
}
MyItem Created 1
MyItem Created 2
...
MyItem Created 15
Subscriber received MyItem(id=1)
Subscriber received MyItem(id=2)
Subscriber received MyItem(id=3)
Subscriber received MyItem(id=4)
Subscriber received MyItem(id=5)
Request two more
Subscriber received MyItem(id=6)
Subscriber received MyItem(id=7)
BUILD SUCCESSFUL in 13s
subscription의 구독을 초기에는 5로 서정했고 5게 이상 부터는 2개식 구독을 진행하는 것으로 수정했다. 걀과를 보면 해당 설정을 이해할 수 있다.
@Test
void single_example() {
Single<String> single = Single.create(
new SingleOnSubscribe<String>() {
@Override
public void subscribe(SingleEmitter<String> emitter) throws Exception {
emitter.onSuccess(DateUtil.getNowDate());
}
}
);
single.subscribe(new SingleObserver<String>() {
@Override
public void onSubscribe(Disposable disposable) {
// 아무것도하지 않음
}
@Override
public void onSuccess(String data) {
Logger.log(LogType.ON_SUBSCRIBE, "# 날짜시각: " + data);
}
@Override
public void onError(Throwable error) {
Logger.log(LogType.ON_ERROR, error);
}
});
}onSuccess()메서드를 통해 소비자의onSuccess()메서드를 호출한다.
onSuccess()생산자에서 발행한 데이터를 해당 메서드에서 소비한다.
- 데이터를 1건만 통지하거나 1건도 통지하지 않고 완료 또는 에러를 통지한다.
- 데이터 통지 자체가 완료를 의미하기 때문에 완료 통지하지 않는다.
- 단, 데이터 1건도 통지하지 않고 처리가 종료될 경우는 완료 통지를 한다.
- Myabe의 대표적인 소비자는 MaybeObserver이다.
@Test
void maybe_example() {
final Maybe<String> maybe = Maybe.create(
new MaybeOnSubscribe<String>() {
@Override
public void subscribe(MaybeEmitter<String> emitter) throws Exception {
// emitter.onSuccess(DateUtil.getNowDate());
emitter.onComplete();
}
}
);
maybe.subscribe(
new MaybeObserver<String>() {
@Override
public void onSubscribe(Disposable disposable) {
// 아무것도하지 않음
}
@Override
public void onSuccess(String data) {
Logger.log(LogType.ON_SUCCESS, data);
}
@Override
public void onError(Throwable error) {
Logger.log(LogType.ON_ERROR, error);
}
@Override
public void onComplete() {
Logger.log(LogType.ON_COMPLETE);
}
}
);
}- 데이터를 1건 이라도 통지하기 때문에
onSuccess()메서드가 호출되면onSuccess() | Test worker | 19:18:15.965 | 2020-09-05 19:18:15출력이 된다. emitter.onSuccess(DateUtil.getNowDate());을 주석하고,emitter.onComplete();을 주석 해제하면 데이터 통제 없이 완료를 통지하면onComplete()메서드가 호출되며onComplete() | Test worker | 19:21:11.959출력이 된다.
- 데이터 생상자이지만 데이터를 1건도 통지하지 않고 완료 또는 에러를 통지한다.
- 데이터 톶지의 역할 대신에 Completable 내에서 특정 작업을 수행한 후, 해당 처리가 끝났음을 통지하는 역할을 한다.
- Completable의 대표적인 소비자는 CompletableObserver이다
@Test
void completable_example() {
final Completable completable = Completable.create(
new CompletableOnSubscribe() {
@Override
public void subscribe(CompletableEmitter emitter) throws Exception {
int sum = 0;
for (int i = 0; i < 100; i++) {
sum = sum + 1;
}
Logger.log(LogType.PRINT, "# 합계: " + sum);
emitter.onComplete();
}
}
);
completable.subscribe(
new CompletableObserver() {
@Override
public void onSubscribe(final Disposable disposable) {
// 아무것도 하지 않음
}
@Override
public void onComplete() {
Logger.log(LogType.ON_COMPLETE);
}
@Override
public void onError(final Throwable error) {
Logger.log(LogType.ON_ERROR, error);
}
}
);
}- RxJava에서의 연산자는 메서드다.
- 연산자를 이용하여 데이터를 생성하고 통지하는 Flowable이나 Observable 등의 생산자를 생성할 수있다.
- Flowable이나 Observable에서 통지한 데이터를 다양한 연산자를 사용하여 가공 처리하여 결과값을 만들어 낸다.
- 연산자의 특성에 따라 카테고리로 분류되며, 본 강의에서는 아래 분류에 속하는 연산자들을 살펴 본다.
- Flowable, Observable 생성 연산자
- 통지된 데이터를 필터링 해주는 연산자
- 통지된 데이터를 변환 해주는 연산자
- 여러 개의 Flowable/Observable을 결합하는 연산자
- 에러 처리 연산자
- 유틸리티 연산자
- 조건가 불린 연산자
- 통지된 데이터를 집계 해주는 연산자
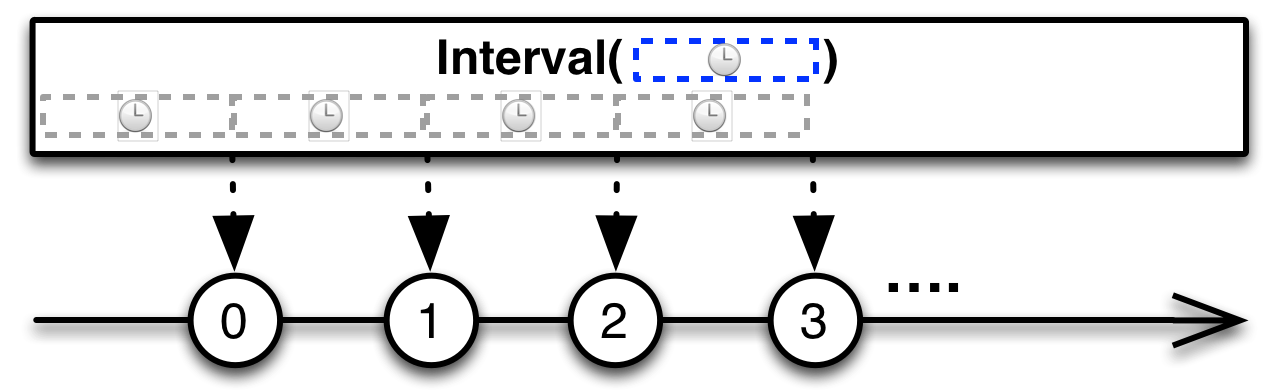
- 지정한 시간 간격 마다 0부터 시작하는 숫자 Long 타입을 통지한다.
- initialDelay 파라미터 이용해서 최초 통지에 대한 대기 시간을 지정할 수 있다.
- 완료 없이 계속 통지한다.
- 호출한 스레드와는 별도의 스레드에서 실행된다.
- Polling 용도의 작업을 수행할 때 활용할 수 있다.
@Test
void observable_interval() {
Observable.interval(0, 1000L, TimeUnit.MILLISECONDS)
.map(num -> num + "count")
.subscribe(data -> Logger.log(LogType.ON_NEXT, data))
;
TimeUtil.sleep(3000L);
}
//onNext() | RxComputationThreadPool-1 | 19:55:18.760 | 0count
//onNext() | RxComputationThreadPool-1 | 19:55:19.750 | 1count
//onNext() | RxComputationThreadPool-1 | 19:55:20.750 | 2count
//onNext() | RxComputationThreadPool-1 | 19:55:21.751 | 3countinterval은 별도의 스레드에서 진행되기 때문에 main 스레드의 sleep이 필요하다.interval(0, 1000L, TimeUnit.MILLISECONDS)0: interval 발동 간격을 0으로 주어 바로 interval이 발동된다1000L, interval의 간격의 값을 지정한다.TimeUnit.MILLISECONDS: interval의 간격의 단위를 결정한다.1000 MILLISECONDS으로 지정되었으니 1초 간격을 갖는다.
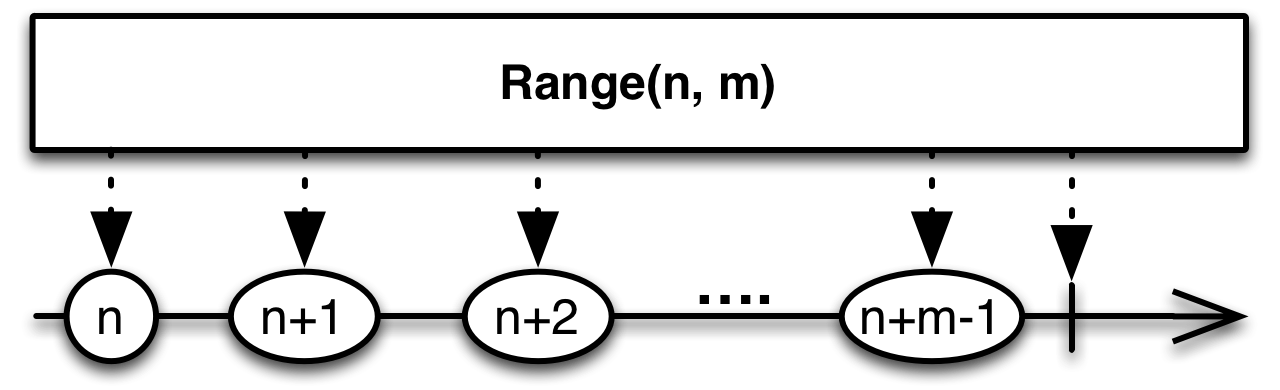
- 지정한 값(n) 부터 m 개의 숫자(Integer)를 통지한다.
for,while문 등의 반복을 대체할 수 있다.
@Test
void observable_range() {
Observable.range(0, 5)
.subscribe(num -> Logger.log(LogType.ON_NEXT, num))
;
}
//onNext() | Test worker | 20:02:09.435 | 0
//onNext() | Test worker | 20:02:09.438 | 1
//onNext() | Test worker | 20:02:09.438 | 2
//onNext() | Test worker | 20:02:09.438 | 3
//onNext() | Test worker | 20:02:09.438 | 4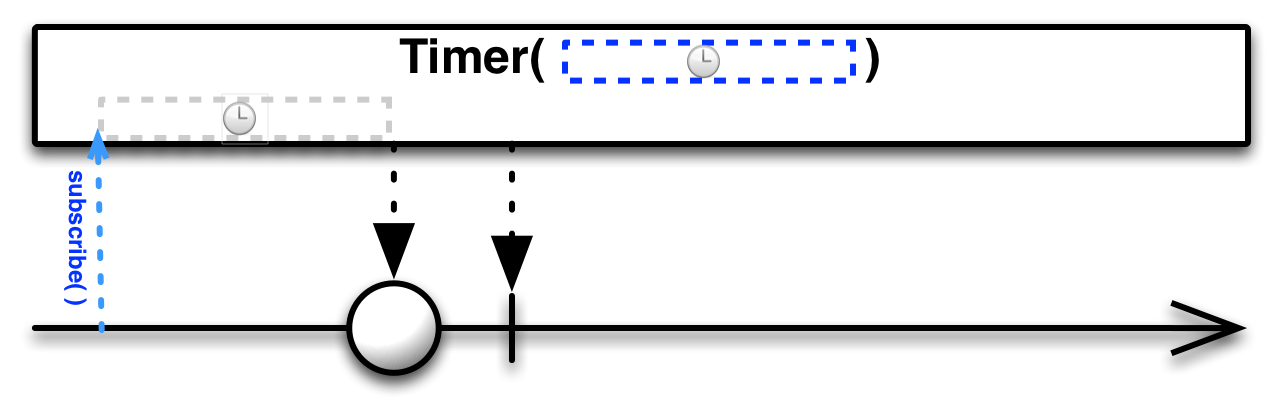
- 지정한 시간이 지나면 0(Long)을 통지한다.
- 0을 통지하고
onComplete()이벤트가 발생하여 종료한다. - 호출한 스레드와는 별도의 스레드에서 실행된다.
- 특정 시간을 대기한 후에 어떤 처리를 하고자 할 때 활용 할 수 있다.
@Test
void observable_timer() {
Logger.log(LogType.PRINT, "# Start");
final Observable<String> observable = Observable.timer(2000, TimeUnit.MILLISECONDS)
.map(count -> "Do work");
observable.subscribe(data -> Logger.log(LogType.ON_NEXT, data));
TimeUtil.sleep(3000L);
//print() | Test worker | 20:09:10.890 | # Start
//onNext() | RxComputationThreadPool-1 | 20:09:12.937 | Do work
}
- 구독이 발생할 때 마다 즉,
subscribe()가 호출될 때마다 새로운Observable을 생성한다. - 선언한 시점의 데이터를 통지하는 것이 아니라 호출 시점의 데이터를 통지한다.
- 데이터 생성을 미루는 효과 있기 때문에 최신 데이터를 얻고자할 때 활용 할 수 있다.
@Test
void observable_defer() {
final Observable<LocalTime> observable = Observable.defer(() -> Observable.just(LocalTime.now()));
final Observable<LocalTime> observableJust = Observable.just(LocalTime.now());
observable.subscribe(timer -> Logger.log(LogType.PRINT, "# defer() 구독1의 구독 시간:" + timer));
observableJust.subscribe(timer -> Logger.log(LogType.PRINT, "# just() 구독1의 구독 시간:" + timer));
TimeUtil.sleep(3000L);
observable.subscribe(timer -> Logger.log(LogType.PRINT, "# defer() 구독2의 구독 시간:" + timer));
observableJust.subscribe(timer -> Logger.log(LogType.PRINT, "# just() 구독2의 구독 시간:" + timer));
}
// print() | Test worker | 20:17:10.016 | # defer() 구독1의 구독 시간:20:17:10.011
// print() | Test worker | 20:17:10.019 | # just() 구독1의 구독 시간:20:17:10.007
// print() | Test worker | 20:17:13.024 | # defer() 구독2의 구독 시간:20:17:13.024
// print() | Test worker | 20:17:13.024 | # just() 구독2의 구독 시간:20:17:10.007just는 스레드 sleep 3초가 적용되지 않갔고,defer는 sleep 3초가 적용된 것을 확인 할 수 있다.just선언 시점의 시간이 출력되지만,defer는 구독한 시점의 시간이 출력된다.defer는subscribe()가 호출될 때마다 새로운Observable을 생성하기 때문에subscribe시점에 새로운 데이터 통지가 시작되는 것이다.

- Iterable 인터페이스를 구현한 클래스를 파라미터로 받는다.
- Iterable에 담긴 데이터를 순서대로 통지한다.
@Test
void observable_iterable() {
final List<String> countries = Arrays.asList("Korea", "Canada", "USA", "Italy");
Observable.fromIterable(countries)
.subscribe(country -> Logger.log(LogType.ON_NEXT, country));
}
//onNext() | Test worker | 20:25:05.306 | Korea
//onNext() | Test worker | 20:25:05.310 | Canada
//onNext() | Test worker | 20:25:05.310 | USA
//onNext() | Test worker | 20:25:05.310 | Italy
- Future 인터페이스는 자바 5에서 비동기 처리를 위해 추가된 동시성 API
- 시간이 오래 걸리는 작업은 Future를 반환하는 ExecutorService에게 맡기고 비동기로 다른 작업을 수행할 수 있다.
- Java 8에서는 CompletableFuture 클래스를 통해 구현이 간결해 졌다.
@Test
void observable_fromFuture() {
Logger.log(LogType.PRINT, "# Start time");
// 긴 처리 시간이 걸리는 작업
Future<Double> future = longTimeWork();
// 짭은 처리 시간이 걸리는 작업
shortTimeWork();
Observable.fromFuture(future)
.subscribe(data -> Logger.log(LogType.PRINT, "# 긴 처리 시간 자업 결과" + data));
Logger.log(LogType.PRINT, "# End time");
//print() | Test worker | 20:40:56.466 | # Start time
//print() | ForkJoinPool.commonPool-worker-9 | 20:40:56.473 | # 긴 처리 시간이 걸리는 작업 중.........
//print() | Test worker | 20:40:59.475 | # 짧은 처리 시간 작업 완료!
//print() | Test worker | 20:41:02.478 | # 긴 처리 시간 자업 결과1.0E17
//print() | Test worker | 20:41:02.478 | # End time
}
- 전달 받은 데이터가 조건에 맞는지 확인 한 후, 결과가 ture인 데이터만 통지한다.
- 파라미터로 받는 Predicate 함수형 인터페이스에서 조건을 확인한다.
@Test
void observable_filter() {
Observable.fromIterable(SampleData.carList)
.filter(car -> car.getCarMaker() == CarMaker.CHEVROLET)
.subscribe(car -> Logger.log(LogType.ON_NEXT, car.getCarMaker() + " : " + car.getCarName()));
}
- 이미 통지된 동일한 데이터가 있다면 이후의 동일한 데이터는 통지 하지 않는다.
@Test
void observable_distinct() {
Observable.fromArray(SampleData.carMakersDuplicated)
.distinct()
.subscribe(carMaker -> Logger.log(LogType.ON_NEXT, carMaker));
}
//onNext() | Test worker | 21:28:04.523 | CHEVROLET
//onNext() | Test worker | 21:28:04.527 | HYUNDAE
//onNext() | Test worker | 21:28:04.527 | SAMSUNG
//onNext() | Test worker | 21:28:04.527 | SSANGYOUNG
//onNext() | Test worker | 21:28:04.527 | KIA
- 파라미터로 지정한 개수나 기간이 될 때까지 데이터를 통지한다.
- 지정한 범위가 통지 데이터보다 클 겨웅 데이터를 모두 통지하고 완료한다.
@Test
void observable_take_개수만큼() {
Observable.just("a", "b", "c", "d")
.take(2)
.subscribeOn(data -> Logger.log(LogType.ON_NEXT, data));
}
@Test
void observable_take_지정한_시간() {
// 1초 간격으로 interval 진행
Observable.interval(1000L, TimeUnit.MILLISECONDS)
.take(3500L, TimeUnit.MILLISECONDS)
.subscribe(data -> Logger.log(LogType.ON_NEXT, data));
// 3.5초 스레드 슬립이기 때문에, 0 ~ 2 까지 소비한다.
TimeUtil.sleep(3500L);
}
//onNext() | RxComputationThreadPool-2 | 21:37:49.051 | 0
//onNext() | RxComputationThreadPool-2 | 21:37:50.045 | 1
//onNext() | RxComputationThreadPool-2 | 21:37:51.045 | 2
- 원본 Observable에서 통지하는 데이터를 원하는 값으로 변환한다.
- 변환 전,후 데이터 타입은 달라도 상관 없다.
- null을 반환하면 NullPointException이 발생하므로 null이 아닌 데이터 하나를 반드시 반환해야한다.
@Test
void observable_map() {
final List<Integer> numbers = Arrays.asList(1, 3, 5, 7);
Observable.fromIterable(numbers)
.map(num -> "1을 더한 결과"+ (num +1))
.subscribe(num -> System.out.println(num));
}
- 원본 데이터를 원하는 값으로 변환 후 통지하는 것은 map과 같다
- map이
1 대 1변환인 것과 달리 flatMap은1 대 다변환이므로 데이터 한개로 여러 데이터를 통지할 수 있다. - map은 변환된 데이터를 변환하지만 flatMap은 변환 된 여러개의 데이터를 담고 있는 새로운 Observable을 반환한다.
- 데이터 통지의 순서를 보장하지 않는다.
@Test
void observable_flat_map() {
Observable.just("Hello")
.flatMap(hello -> Observable.just("JAVA", "Kotlin", "Spring").map(lang -> hello + ", " + lang))
.subscribe(data -> System.out.println(data));
//Hello, JAVA
//Hello, Kotlin
//Hello, Spring
}
- 원본 데이터와 변환된 데이터를 조합해서 새로운 데이터를 통지한다.
- 즉, Observable에 원본 데이터 + 반환된 데이터 = 최종 데이터를 실어서 반환한다.
@Test
void observable_flat_map_3() {
Observable.range(2, 1)
.flatMap(
data -> Observable.range(1, 9),
(sourceData, transformedData) -> sourceData + " * " + transformedData + " = "
+ sourceData * transformedData
)
.subscribe(System.out::println);
}- 최종적으로 한번더 람다 표현식으로 데이터를 가공한(2차 가공) 이후 보낸다.

- flatMap과 마찬가지로 받은 데이터를 변환하여 새로운 Observable로 변환한다.
- 반환된 새로운 Observable을 하나씩 순서대로 실행하는 것이 FlatMap과 다르다.
- 즉, 데이터의 처리 순서는 보장하지만 처리중인 Observable의 처리가 끝나야 다음 Observable이 실행되므로 처리 성능에 영향을 줄 수 있다.
@Test
void observable_concat_map() {
TimeUtil.start();
Observable.interval(100L, TimeUnit.MILLISECONDS)
.take(4)
.skip(2)
.concatMap(
num -> Observable.interval(200L, TimeUnit.MILLISECONDS)
.take(10)
.skip(1)
.map(row -> num + " * " + row + " = " + num * row)
)
.subscribe(
data -> Logger.log(LogType.ON_NEXT, data),
error -> {
},
() -> {
TimeUtil.end();
TimeUtil.takeTime();
}
);
TimeUtil.sleep(5000L);
}
- 데이터를 변환하여 새로운 Observable로 변환한다.
- concatMap과 다른 점은 switchMap은 순서를 보장하지만 새로운 데이터가 동지되면 현재 처리중이던 작업을 바로 중단한다.
@Test
void void_observable_switch_map() {
TimeUtil.start();
Observable.interval(100L, TimeUnit.MILLISECONDS)
.take(4)
.skip(2)
.doOnNext(data -> Logger.log(LogType.DO_ON_NEXT, data))
.switchMap(
num -> Observable.interval(300L, TimeUnit.MILLISECONDS)
.take(10)
.skip(1)
.map(row -> num + " * " + row + " = " + num * row)
)
.subscribe(data -> Logger.log(LogType.ON_NEXT, data));
TimeUtil.sleep(5000L);
}
//doOnNext() | RxComputationThreadPool-1 | 23:10:34.990 | 2
//doOnNext() | RxComputationThreadPool-1 | 23:10:35.085 | 3
//onNext() | RxComputationThreadPool-3 | 23:10:35.690 | 3 * 1 = 3
//onNext() | RxComputationThreadPool-3 | 23:10:35.990 | 3 * 2 = 6
//onNext() | RxComputationThreadPool-3 | 23:10:36.290 | 3 * 3 = 9
//onNext() | RxComputationThreadPool-3 | 23:10:36.589 | 3 * 4 = 12
//onNext() | RxComputationThreadPool-3 | 23:10:36.890 | 3 * 5 = 15
//onNext() | RxComputationThreadPool-3 | 23:10:37.186 | 3 * 6 = 18
//onNext() | RxComputationThreadPool-3 | 23:10:37.490 | 3 * 7 = 21
//onNext() | RxComputationThreadPool-3 | 23:10:37.787 | 3 * 8 = 24
//onNext() | RxComputationThreadPool-3 | 23:10:38.091 | 3 * 9 = 27doOnNext :2, doOnNext: 3이 출력되었다switchMap2를 전달받지만interval에서 0.3초가 지나지 않아 통지를 하지 않고 있다.- 그 와중에 밖안쪽
interval에서 다시 0.1초 뒤에 3을 전달 받게된다. - switchMap은 새로운 데이터가 동지되면 현재 처리중이던 작업을 바로 중단한다. 그래서 3단만 출력을 진행한다.

- 하나의 Observable을 여러개의 새로운 GroupedByObservable로 만든다.
- 원본 Observable의 데이터를 그룹별로 묶는다기보다는 각각의 데이터들이 그룹에 해당하는 key를 가지게 된다.
- GroupedByOservable은 getKey()를 통해 구분된 그룹을 알 수 있게 해준다.
@Test
void observable_group_by() {
Observable<GroupedObservable<CarMaker, Car>> observable = Observable.fromIterable(SampleData.carList)
.groupBy(car -> car.getCarMaker());
observable.subscribe(
groupedObservable -> groupedObservable.subscribe(
car -> Logger.log(
LogType.ON_NEXT,
"Group: " + groupedObservable.getKey() + "\t Car name: " + car.getCarName()
)
)
);
}
- 통지 되는 데이터를 모두 List에 담아 통지한다.
- 원본 Observable 에서 완료 통지를 받는 즉시 리스트를 통지한다.
- 통지되는 데이터는 원본 데이터를 담은 리스트 하나이므로 Single로 반환된다.
@Test
void observable_to_list() {
final Single<List<Integer>> single = Observable.just(1, 3, 5, 7, 9).toList();
single.subscribe(System.out::println);
}
- 통지 되는 데이터를 모두 Map에 담아 통지한다.
- 원본 Observable 에서 완료 통지를 받는 즉시 Map을 통지한다.
- 이미 사용중인 key를 또 생성하면 기존에 있던 key와 value를 덮어 쓴다.
- 통지되는 데이터는 원본 데이터를 담은 Map 하나 이므로 Single로 반환된다.
@Test
void observable_to_map() {
final Single<Map<String, String>> single = Observable.just("a-1", "b-1", "c-1", "d-1")
.toMap(data -> data.split("-")[0]);
single.subscribe(System.out::println);
}

- 다수의 Observable에서 통지된 데이터를 받아 다시 하나의 Observable로 통지한다.
- 통지 시점이 빠른 Observable의 데이터부터 순차적으로 통지되고 통지 시점이 같을 경우에는 merge() 함수의 파라미터로 먼저 지정된 Observable의 데이터부터 통지된다.
@Test
void observable_merge() {
final Observable<Long> observable1 = Observable.interval(200L, TimeUnit.MILLISECONDS)
.take(5);
final Observable<Long> observable2 = Observable.interval(400L, TimeUnit.MILLISECONDS)
.take(5)
.map(num -> num + 1000);
Observable.merge(observable1, observable2)
.subscribe(data -> System.out.println(data));
TimeUtil.sleep(4000);
//onNext() | RxComputationThreadPool-1 | 23:02:46.424 | 0
//onNext() | RxComputationThreadPool-1 | 23:02:46.619 | 1
//onNext() | RxComputationThreadPool-2 | 23:02:46.620 | 1000
//onNext() | RxComputationThreadPool-1 | 23:02:46.817 | 2
//onNext() | RxComputationThreadPool-1 | 23:02:47.016 | 3
//onNext() | RxComputationThreadPool-1 | 23:02:47.017 | 1001
//onNext() | RxComputationThreadPool-1 | 23:02:47.219 | 4
//onNext() | RxComputationThreadPool-2 | 23:02:47.419 | 1002
//onNext() | RxComputationThreadPool-2 | 23:02:47.816 | 1003
//onNext() | RxComputationThreadPool-2 | 23:02:48.219 | 1004
}
- 다수의 Observable에서 통지된 데이터를 받아서 다시 하나의 Observable로 통지한다.
- 하나의 Observable에서 통지가 끝나면 다음 Observable에서 연이어 통지가 된다.
- 각 Observable의 통지 시점과는 상관 없이
concat()함수의 파라미터로 먼저 입력된 Observable의 데이터부터 모두 통지 된 후, 다음 Observable의 데이터가 통지된다.
@Test
void observable_concat() {
final Observable<Long> observable1 = Observable.interval(500L, TimeUnit.MILLISECONDS)
.take(5);
final Observable<Long> observable2 = Observable.interval(300L, TimeUnit.MILLISECONDS)
.take(5)
.map(num -> num + 1000);
Observable.concat(observable1, observable2)
.subscribe(data -> Logger.log(LogType.ON_NEXT, data));
TimeUtil.sleep(4000);
//onNext() | RxComputationThreadPool-1 | 23:07:29.037 | 0
//onNext() | RxComputationThreadPool-1 | 23:07:29.528 | 1
//onNext() | RxComputationThreadPool-1 | 23:07:30.031 | 2
//onNext() | RxComputationThreadPool-1 | 23:07:30.529 | 3
//onNext() | RxComputationThreadPool-1 | 23:07:31.031 | 4
//onNext() | RxComputationThreadPool-2 | 23:07:31.333 | 1000
//onNext() | RxComputationThreadPool-2 | 23:07:31.634 | 1001
//onNext() | RxComputationThreadPool-2 | 23:07:31.936 | 1002
//onNext() | RxComputationThreadPool-2 | 23:07:32.236 | 1003
//onNext() | RxComputationThreadPool-2 | 23:07:32.533 | 1004
}
- 다수의 Observable에서 통지된 데이터를 받아서 다시 하나의 Observable로 통지한다.
- 각 Observable에서 통지된 데이터가 모두 모이면 각 Observable에서 동일한 index의 데이터로 새로운 데이터를 생성한 후 통지한다.
- 통지하는 데이터 개수가 가장 적은 Observable의 통지 시점에 완료 통지 시점을 맞춘다.
@Test
void obserable_zip() {
final Observable<Long> observable1 = Observable.interval(200L, TimeUnit.MILLISECONDS)
.take(4);
final Observable<Long> observable2 = Observable.interval(400L, TimeUnit.MILLISECONDS)
.take(6);
Observable.zip(observable1, observable2, (data1, data2) -> data1 + data2)
.subscribe(data -> Logger.log(LogType.ON_NEXT, data));
TimeUtil.sleep(4000);
//onNext() | RxComputationThreadPool-1 | 23:13:03.795 | 0
//onNext() | RxComputationThreadPool-2 | 23:13:04.189 | 2
//onNext() | RxComputationThreadPool-2 | 23:13:04.589 | 4
//onNext() | RxComputationThreadPool-2 | 23:13:04.989 | 6
}
- 다수의 Observable에서 통지된 데이터를 받아서 하나의 Observable로 통지한다.
- 각 Observable에서 데이터를 통지할 때마다 모든 Observable에서 마지막으로 통지한 각 데이터를 함수형 인터페이스에 전달하고, 새로운 데이터를 통지한다.
@Test
void observable_combineLatest() {
final Observable<Long> observable1 = Observable.interval(500L, TimeUnit.MILLISECONDS)
.take(4);
final Observable<Long> observable2 = Observable.interval(700L, TimeUnit.MILLISECONDS)
.take(4);
Observable.combineLatest(observable1, observable2, (data1, data2) -> "data1: " + data1 + "\tdata2: " + data2)
.subscribe(data -> Logger.log(LogType.ON_NEXT, data));
TimeUtil.sleep(4000);
//onNext() | RxComputationThreadPool-2 | 00:03:19.345 | data1: 0 data2: 0
//onNext() | RxComputationThreadPool-1 | 00:03:19.639 | data1: 1 data2: 0
//onNext() | RxComputationThreadPool-2 | 00:03:20.037 | data1: 1 data2: 1
//onNext() | RxComputationThreadPool-1 | 00:03:20.139 | data1: 2 data2: 1
//onNext() | RxComputationThreadPool-1 | 00:03:20.639 | data1: 3 data2: 1
//onNext() | RxComputationThreadPool-2 | 00:03:20.739 | data1: 3 data2: 2
//onNext() | RxComputationThreadPool-2 | 00:03:21.439 | data1: 3 data2: 3
}@Test
void try_catch_사용하지_못한다() {
try {
Observable.just(2)
.map(num -> num / 0)
.subscribe(System.out::println);
} catch (Exception e) {
System.out.println("error logging..."); // 로긍 출력안됨
}
// Exception in thread "Test worker" io.reactivex.exceptions.OnErrorNotImplementedException: The exception was not handled due to missing onError handler in the subscribe() method call. Further reading: https://github.com/ReactiveX/RxJava/wiki/Error-Handling | java.lang.ArithmeticException: / by zero
}- 리액티브 프로그래밍에서 일반적인
try-catch방식으로 에러를 해결 할 수 없고,onError()에서 해당error를 받아서 처리하는 구조를 가져야한다.
@Test
void error_handle() {
Observable.just(5)
.flatMap(num -> Observable.interval(200L, TimeUnit.MILLISECONDS)
.doOnNext(data -> Logger.log(LogType.DO_ON_NEXT, data))
.take(5)
.map(i -> num / i))
.subscribe(
data -> Logger.log(LogType.ON_NEXT, data),
error -> Logger.log(LogType.ON_ERROR, error),
() -> Logger.log(LogType.ON_COMPLETE)
);
TimeUtil.sleep(1000L);
//doOnNext() | RxComputationThreadPool-1 | 00:15:06.325 | 0
//onERROR() | RxComputationThreadPool-1 | 00:15:06.330 | java.lang.ArithmeticException: / by zero
}- 일반적으로
onError()에서 해당error를 위 처럼 처리할 수 있다.

- 에러가 발생했을 때 에러를 의미하는 데이터로 대체할 수 있다.
onErrorReturn()을 호출하면onError이벤트는 발생하지 않는다.
@Test
void onErrorReturn() {
Observable.just(5)
.flatMap(num -> Observable.interval(200L, TimeUnit.MILLISECONDS)
.doOnNext(data -> Logger.log(LogType.DO_ON_NEXT, data))
.take(5)
.map(i -> num / i)
.onErrorReturn(ex -> {
if (ex instanceof ArithmeticException) {
Logger.log(LogType.PRINT, "게산 처리 에러 발생" + ex.getMessage());
}
return -1L;
})
)
.subscribe(
data -> {
if (data < 0) {
Logger.log(LogType.PRINT, "예외를 알리는 데이터: " + data);
} else {
Logger.log(LogType.ON_NEXT, data);
}
},
error -> Logger.log(LogType.ON_ERROR, error),
() -> Logger.log(LogType.ON_COMPLETE)
);
TimeUtil.sleep(1000L);
}onErrorReturn를 이용하면 소비자의onError에 통지되지 않고,onNext에 통지된다. 즉 에러가 발생하기 전에 사전에 처리 가능하다. 모든 에러를 소비자쪽에서 할 수 없다.- 에러로 통지된
onNext에서 구분 가능한 값으로 분기를 처리해서 에러를 처리한다.

- 에러가 발생했을 때 에러를 의미하는 Observable로 대체할 수 이싿.
- Observable로 대체할 수 있으므로 데이터 교체와 더불어 에러 처리를 위한 추가 작업을 할 수 있다.
@Test
void observable_onErrorResumeNext() {
Observable.just(5)
.flatMap(num -> Observable.interval(200L, TimeUnit.MILLISECONDS)
.doOnNext(data -> Logger.log(LogType.DO_ON_NEXT, data))
.take(5)
.map(i -> num / i)
.onErrorResumeNext(throwable -> {
Logger.log(LogType.PRINT, "운영제에게 이메일 발송 " + throwable.getMessage());
return Observable.interval(200L, TimeUnit.MILLISECONDS).take(5).skip(1).map(i -> num / i);
})
).subscribe(data -> Logger.log(LogType.ON_NEXT, data));
TimeUtil.sleep(2000L);
//doOnNext() | RxComputationThreadPool-1 | 00:33:20.607 | 0
//print() | RxComputationThreadPool-1 | 00:33:20.610 | 운영제에게 이메일 발송 / by zero
//onNext() | RxComputationThreadPool-2 | 00:33:21.015 | 5
//onNext() | RxComputationThreadPool-2 | 00:33:21.212 | 2
//onNext() | RxComputationThreadPool-2 | 00:33:21.416 | 1
//onNext() | RxComputationThreadPool-2 | 00:33:21.613 | 1
}- 에러가 발생하면
onErrorResumeNext에서 새로운 데이터를 통지한다. .skip(1)를 통해서 에러가 발생하면 skip을 진행한다.

- 데이터 통지 중에 에러가 발생했을 때, 데이터 통지를 재시도 한다.
- 즉, onError 이벤트가 발생하면 subscribe() 재시도한다.
@Test
void observable_retry() {
Observable.just(5)
.flatMap(num -> Observable.interval(200L, TimeUnit.MILLISECONDS)
.map(i -> {
long result;
try {
result = num / i;
} catch (ArithmeticException e) {
Logger.log(LogType.PRINT, "error: " + e.getMessage());
throw e;
}
return result;
})
.retry(5)
.onErrorReturn(throwable -> -1L)
)
.subscribe(
data -> Logger.log(LogType.ON_NEXT, data),
error -> Logger.log(LogType.ON_ERROR, error),
() -> Logger.log(LogType.ON_COMPLETE)
);
TimeUtil.sleep(5000L);
//print() | RxComputationThreadPool-1 | 00:41:50.215 | error: / by zero
//print() | RxComputationThreadPool-2 | 00:41:50.422 | error: / by zero
//print() | RxComputationThreadPool-3 | 00:41:50.625 | error: / by zero
//print() | RxComputationThreadPool-4 | 00:41:50.826 | error: / by zero
//print() | RxComputationThreadPool-5 | 00:41:51.028 | error: / by zero
//print() | RxComputationThreadPool-6 | 00:41:51.231 | error: / by zero
//onNext() | RxComputationThreadPool-6 | 00:41:51.232 | -1
//onComplete() | RxComputationThreadPool-6 | 00:41:51.232
}- 두 번째
error: / by zero부터는retry()메서를 통해서 재시도를 진행한다.

- 생산자가 데이터를 생성 및 통지를 하지 설정한 시간만큼 소비자쪽의 데이터 전달을 지연시킨다.
@Test
void observable_delay() {
Logger.log(LogType.PRINT, "실행 시간: " + TimeUtil.getCurrentTimeFormatted());
Observable.just(1, 3, 4, 6)
.doOnNext(data -> Logger.log(LogType.DO_ON_NEXT, data))
.delay(200, TimeUnit.MILLISECONDS)
.subscribe(data -> Logger.log(LogType.ON_NEXT, data));
}
- 생산자가 데이터의 생성 및 통지 자체를 설정한 시간만큼 지연시킨다.
- 죽, 소비자가 구독을 해도 구독 시점 자체가 지연된다.
@Test
void obsesrvable_delaySubscription() {
Logger.log(LogType.PRINT, "실행 시간: " + TimeUtil.getCurrentTimeFormatted());
Observable.just(1, 3, 4, 6)
.doOnNext(data -> Logger.log(LogType.DO_ON_NEXT, data))
.delaySubscription(200, TimeUnit.MILLISECONDS)
.subscribe(data -> Logger.log(LogType.ON_NEXT, data));
}
- 각각의 데이터 통지 시, 지정된 시간안에 통지가 되지 않으면 에러를 통지한다.
- 에러 통지 시 전달되는 에러 객체는 TimeoutException이다.
@Test
void observable_timeout() {
Observable.range(1, 5)
.map(num -> {
long time = 1000L;
if (num == 4) {
time = 1500L;
}
TimeUtil.sleep(time);
return num;
})
.timeout(1200L, TimeUnit.MICROSECONDS)
.subscribe(
data -> Logger.log(LogType.ON_NEXT, data),
error -> Logger.log(LogType.ON_ERROR, error)
);
TimeUtil.sleep(4000L);
}
- 각각의 데이터가 통지된느데 걸리는 시간을 통지한다.
- 통지된 데ㅣㅇ터와 데이터가 통지되는데 걸리는 시간을 소비자쪽에서 모두 처리할 수 있다.
@Test
void observable_timeInterval() {
Observable.just(1, 3, 5, 6, 9)
.delay(item -> {
TimeUtil.sleep(NumberUtil.randomRange(100, 1000));
return Observable.just(item);
})
.timeInterval()
.subscribe(
timed -> Logger
.log(LogType.ON_NEXT, "통지하는데 걸리는 시간: " + timed.toString() + "\t 통지된 데이터: " + timed.value())
);
}
- 물리적인 스레드는 하드웨어와 관련이 있고, 논리적인 스레드는 소프트웨어와 연관이 있다.
- 물리적인 스레드는 물리적인 코어를 놀리적으로 쪼갠 논리적 코어이다.

- 물리적인 스레드는 자바 프로그래밍에서 사용하는 그 스레드가 논리적인 스레드이다.
- 논리적인 스레드는 프로레스에서 실행되는 세부 작업의 단위이다.
- 논리적인 스레드의 생성 개수는 이론적으로 제한이 없지만 실제로 물리적인 스레드의 사용 범위내에서 생성할 수 있다.
- CPU Core에는 그 개수가 정해져있음, 물리적 스레드는 병렬성을 가지고 있음, 동일한 시간에 여러 스레드가 병렬로 실행이 가능하다
- 소프트웨어 프로새스의 논리적 스레드는 동시성을 가지고 있음, 병렬처럼 실행되는 것처럼 보이지만 여러개의 작업들이 짧은 시간에 실행되는 구조이다.
- 논리적 스레드를 물리적인 스레드 보다 더 많이 생성한 이후 물리적인 스레드를 번갈아 가면서 실행한다.
프로그래밍 패러다임으로서, 동시 컴퓨팅은 모듈화 프로그래밍의 한 형태다. 즉 전체 계산을 작은 단위의 계산으로 분해해 동시적으로 실핼할 수 있다.
동시성은 전체 작업을 작은 부분으로 나눠 동시에 실행하는 것이다.
결론은 동시성은 병렬화를 통해서 이뤄지지만 동일한 것은 아니다. 오히려 동시성을 당성할 수 있는 방법에 관한것이다.
기본적으로 옵저버블과 이에 적용된 연산자 체인은 subscribe가 호출된 동일한 스레드에서 작업을 수행하며, 옵저버가 onComplete 또는 onError 알림을 수신할 때까지 스레드가 차단된다. 스케줄러를 사용하면 이것을 변경할 수 있다.
스케줄러는 스레드 풀로 생각하면 된다. 스케줄러를 사용해 ReactiveX는 스레드풀을 생성하고 스레드를 실행할 수 있다. ReactiveX에서 이것을 기본적으로 멀티 스레딩과 동시성을 추상화한것으로 동시성 구현을 훨씬 쉽게 만들어준다.
- RxJava에서의 스케줄러는 Rxava 비동기 프로그래밍을 위한 스레드 관리자이다.
- 즉, 스케줄러를 이용해서 어떤 스레드에사ㅓ 무엇을처리할 지에 대해서 제어할 수 있다.
- 스케줄러를 이용해 데이터를 통지하는 쪽과 데이터를 처리하는 쪽 스레드를 별도로 지정해서 분리할 수 있다.
- RxJava에서 스케줄러를 지정하기 위해서는
subscribeOn(),observeOn()우틸리티 연산자를 사용한다.- 생산자쪽의 데이터 흐름을 제어하기 위해서는
subscribeOn()연산자를 사용 - 소비자쪽에서 전달받은 데이터를 처리를 제어하기 위해서는
observeOn()연산자를 사용
- 생산자쪽의 데이터 흐름을 제어하기 위해서는
Schedulers.io()는 I/O 관련 스레드를 제공한다. 좀 더 정확하게 말하자면 Schedulers.io()는 I/O 관련 작업을 수행 할 수 있는 무제한의 워커 스레드를 생성하는 스레드풀을 제공한다. 이 풀의 모든 스레드는 블로킹이고 I/O 작업을 더 많이 수행하도록 작성했기 때문에 계산 집약적인 작업보다 CPU 부하는 적지만 대기중인 I/O 작업으로 인해 조금 더 오래걸릴 수 있다. I/O 작업은 파일시스템, 데이터베이스, 서비스 또는 I/O 장치와의 상호작용을 의미한다. 메모리가 허용하는 무제한의 스레드를 생성해 OutOfMemory 오류를 일으킬 수 있이므로 이 스케줄러를 사용할 때는 주의해야한다. 스레드 풀에서 스레드를 가져오나 가져올 스레드가 없으면 새로운 스레드를 생성한다.
Schedulers.computation()는 아마도 프로그래머에게 가장 유용한 스케줄러일것이다. 이것은 사용 가능한 CPU 코어와 동일한 수의 스레드를 가지는 제한된 스레드풀을 제공한다. 이 스케줄러는 CPU를 주로 사용하는 작업을 위한 것이다. Schedulers.computation()는 CPU 집중적인 작업에만 사용해야하며 다른 종류의 작업에 사용해서는 안된다. 그 이유는 이 스케줄러의 스레드가 CPU 코어를 사용 중인 상태로 유지하는데, I/O 관련이나 계산과 관련되지 않은 작업에 사용되는 경우 전체 애플리케이션의 속도를 저하시킬 수 있기 때문이다.
I/O에 관련된 작업에는 Schedulers.io를 사용하고 계산 목적에는 Schedulers.computation()을 고려해야 하는 주된 이유는 computational() 스레드가 프로세스를 더 잘 활용하며 사용 가능한 CPU 코어보다 더 많은 스레드를 생성하지 않고 스레드를 재사용하기 때문이다. Schedulers.io()는 무제한 스레드를 제공하고 있는데 io 블럭에서 10,000개의 계산 작업을 병렬로 예약하는 경우 10,000 개의 작업은 각각 자체 스레드를 가지게 되므로 CPU를 놓고 서로 경쟁하게 된다. 이는 컨텍스트 전환비용을 발생 시킨다.
Schedulers.newThread()는 제공된 각 작업에 대해 새 스레드를 만드는 스케줄러를 제공한다. 언뜻 보기에는 Schedulers.io()와 비슷하게 보일 수 있지만 실제로는 큰 차이가 있다. Schedulers.io()는 스레드 풀을 사용하고 새로운 작업을 할당 받을 때마다 먼저 스레드풀을 조사해 유휴 스레드가 해당 작업을 실행할 수 있는지를 확인한다. 작업을 시작 하기 위해 기존의 스레드를 사용할 수 없으므로 새로운 스레드를 생성한다. 그러나 Schedulers.newThread()는 스레드 풀을 사용하지 않는다. 대신 모든 요청에 대해 새로운 스레드를 생성하고 그 사실을 잊어버린다. 대부분의 경우 Schedulers.computation()을 사용하고 그렇지 않은 경우 Schedulers.io()를 고려해야하며 Schedulers.newThread()는 사용하지 않는 것이 좋다, 스레드는 매우 비싼 자원이므로 새 스레드를 가능한 많이 만들지 않도록 노력해야한다.
Schedulers.single()는 하나의 스레드만 포함하는 스케줄러를 제공하고 모든 호출에 대해 단일 인스턴스를 반환한다. 반드시 순차적으로 작업을 실행해야 하는 상황에서 가장 유용한 옵션이다. 하나의 스레드만 제공하믈 여기에 대기중인 모든 작업은 순차적으로 실행될 수 있다.
Schedulers.single(), Schedulers.trampoline() 두 개의 스케줄러는 모두 순차적으로 실행된다. Schedulers.single()는 모든 작업이 순차적으로 실행되도록 보장하지만 호출된 스레드와 병렬로 실행될 수 있다. 그 부분이 Schedulers.trampoline()와 다르다.
애플리케이션을 개발하는 동안 사용자가 정의한 스케줄러를 원할 수 있다. 이런 경우 Schedulers.from()을 사용하면 된다.
@Test
fun `subscribeOn 연산자`() {
listOf("1", "2", "3", "4", "5", "6", "7", "8", "9", "10")
.toObservable()
.map {
println("Mapping $it ${Thread.currentThread().name}")
return@map it.toInt()
}
.subscribe {
println("Recived $it ${Thread.currentThread().name}")
}
}Mapping 1 Test worker
Recived 1 Test worker
Mapping 2 Test worker
Recived 2 Test worker
Mapping 3 Test worker
Recived 3 Test worker
Mapping 4 Test worker
Recived 4 Test worker
Mapping 5 Test worker
Recived 5 Test worker
Mapping 6 Test worker
Recived 6 Test worker
Mapping 7 Test worker
Recived 7 Test worker
Mapping 8 Test worker
Recived 8 Test worker
Mapping 9 Test worker
Recived 9 Test worker
Mapping 10 Test worker
Recived 10 Test worker
출력을 확인 해보면 Test workcer 스레드가 전체 구독을 실행하는 것을 확인 할 수 있다.
@Test
fun `subscribeOn 연산자`() {
listOf("1", "2", "3", "4", "5", "6", "7", "8", "9", "10")
.toObservable()
.map {
println("Mapping $it ${Thread.currentThread().name}")
return@map it.toInt()
}
.subscribeOn(Schedulers.computation())
.subscribe {
println("Received $it ${Thread.currentThread().name}")
}
runBlocking { delay(1000) }}
}Mapping 1 RxComputationThreadPool-1
Received 1 RxComputationThreadPool-1
Mapping 2 RxComputationThreadPool-1
Received 2 RxComputationThreadPool-1
Mapping 3 RxComputationThreadPool-1
Received 3 RxComputationThreadPool-1
Mapping 4 RxComputationThreadPool-1
Received 4 RxComputationThreadPool-1
Mapping 5 RxComputationThreadPool-1
Received 5 RxComputationThreadPool-1
Mapping 6 RxComputationThreadPool-1
Received 6 RxComputationThreadPool-1
Mapping 7 RxComputationThreadPool-1
Received 7 RxComputationThreadPool-1
Mapping 8 RxComputationThreadPool-1
Received 8 RxComputationThreadPool-1
Mapping 9 RxComputationThreadPool-1
Received 9 RxComputationThreadPool-1
Mapping 10 RxComputationThreadPool-1
Received 10 RxComputationThreadPool-1
@Test
fun `subscribeOn 연산자`() {
listOf("1", "2", "3", "4", "5", "6", "7", "8", "9", "10")
.toObservable()
.map { item ->
println("Mapping $item ${Thread.currentThread().name}")
return@map item.toInt()
}
.subscribeOn(Schedulers.computation())
.observeOn(Schedulers.io())
.subscribe { item ->
println("Received $item ${Thread.currentThread().name}")
}
runBlocking { delay(1000) }
}Mapping 1 RxComputationThreadPool-1
Mapping 2 RxComputationThreadPool-1
Mapping 3 RxComputationThreadPool-1
Mapping 4 RxComputationThreadPool-1
Mapping 5 RxComputationThreadPool-1
Received 1 RxCachedThreadScheduler-1
Mapping 6 RxComputationThreadPool-1
Received 2 RxCachedThreadScheduler-1
Mapping 7 RxComputationThreadPool-1
Received 3 RxCachedThreadScheduler-1
Mapping 8 RxComputationThreadPool-1
Received 4 RxCachedThreadScheduler-1
Mapping 9 RxComputationThreadPool-1
Received 5 RxCachedThreadScheduler-1
Mapping 10 RxComputationThreadPool-1
Received 6 RxCachedThreadScheduler-1
Received 7 RxCachedThreadScheduler-1
Received 8 RxCachedThreadScheduler-1
Received 9 RxCachedThreadScheduler-1
Received 10 RxCachedThreadScheduler-1
subscribeOn은 그 자체로 휼륭해 보이지만 어떤 경우엔느 접합하지 않을 수 있다. 예를들어 computation 스레드에서 계산을 수행하고 io 스레드에서 결과를 표시하도록 할 수 있다. subscribeOn 연산자는 이런 요구사항을 위해서 동료가 필요하다. 전체 구독에 대해서 스레드를 지정하지만 특연 연산자에 대한 스레드를 지정하려면 도움이 필요하다.
subscribeOn 연사자의 완벽한 동료는 observeOn 연산자아다. observeOn 연산자는 그 후에 호출되는 모든 연산자에 스케줄러를 지정한다.
위 예제는 subscribeOn(Schedulers.computation())를 호출해 computation 스레드를 지정했고, 그 결과를 받기 위해 observeOn(Schedulers.io())를 호출해 io 스레드로 전달했다.