본 포스팅은 Spring Data MongoDB에서 발생하는 N+1 문제를 중심으로, 성능 관점에서의 문제점과 이를 개선하기 위한 최적화 전략을 상세하게 다루고자 합니다. 특히, 연관 데이터를 로딩할 때 불필요한 추가 조회로 인한 성능 저하 문제를 해결하기 위해 @DBRef의 lazy 옵션 활용, $lookup 기반의 Aggregation 쿼리, 그리고 단순 값 객체 기반의 연관관계 모델링 등 여러 접근 방식을 비교 분석합니다.
Spring Data MongoDB에서는 @DBRef 애노테이션을 사용하여 객체 간의 연관관계를 정의할 수 있습니다. 이 방식은 문서 내부에 참조 대상 컬렉션의 이름과 해당 문서의 ID를 함께 저장함으로써, 필요 시 연관 문서를 로딩할 수 있도록 지원합니다. 예를 들어, 아래 JSON 예시와 같이 Post 문서의 author 필드에 "author"라는 컬렉션 이름과 실제 Author 문서의 ID가 기록됩니다.
{
"_id": {
"$oid": "67c49519bb7bbd62011d7b13"
},
"author": {
"$ref": "author",
"$id": "67c49518bb7bbd62011d7b0e"
},
"content": "content-1",
"title": "title-1"
}이 방식은 MongoDB의 데이터 모델을 명확하게 정의하는 데 도움을 주지만, 연관 문서를 로딩할 때 별도의 추가 조회 쿼리가 실행되는 단점이 있습니다. 즉, Post 문서를 조회한 후 해당 Author 문서에 접근하면 각 Post마다 추가 조회가 발생하여, 특히 대량의 데이터를 다룰 때 N+1 문제가 발생할 위험이 있습니다.
따라서, @DBRef를 사용할 때는 lazy 로딩 옵션을 활용하거나, 필요에 따라 $lookup 연산자를 이용해 단일 Aggregation 쿼리로 연관 데이터를 한 번에 조회하는 등 최적화 전략을 고려하는 것이 중요합니다.
앞으로 본 포스팅에서는 위에서 언급한 최적화 전략들을 중심으로, 각 방식의 실제 동작 방식과 성능 차이를 구체적으로 분석하고, 상황에 맞는 최적의 설계 방법을 제시하는 내용을 다루겠습니다.
DBRef 방식은 Spring Data MongoDB에서 객체 간의 연관관계를 손쉽게 표현할 수 있도록 해줍니다. 이 방식은 문서 내부에 참조 대상 컬렉션의 이름과 ID를 함께 저장하여, 필요할 때 연관 문서를 자동으로 로딩할 수 있습니다. 예를 들어, 아래의 코드에서는 Post 도큐먼트에서 @DBRef 애노테이션을 사용하여 Author 객체를 참조하고 있습니다.
@Document(collection = "post")
class Post(
@Id
var id: ObjectId? = null,
@Field(name = "title")
val title: String,
@Field(name = "content")
val content: String,
@DBRef(lazy = false)
val author: Author
)
@Document(collection = "author")
class Author(
@Id
var id: ObjectId? = null,
@Field(name = "name")
val name: String
)이 코드에서 lazy = false로 설정되어 있기 때문에, Post를 조회할 때 관련 Author 문서가 함께 즉시 로딩됩니다. 그러나 자동 로딩 기능은 각 문서를 조회할 때마다 추가 조회 쿼리를 발생시킬 수 있어, 많은 데이터를 조회하는 경우 N+1 문제가 발생할 위험이 있습니다. 따라서, 상황에 따라 lazy 옵션을 적절히 설정하여 불필요한 데이터 로딩을 방지하는 것이 중요합니다.
@DBRef(lazy = false)를 사용하면 Post를 조회할 때 연관된 Author 문서를 즉시 로딩합니다. 이 경우, Post마다 Author를 조회하기 때문에 다수의 Post를 조회하면 각각에 대해 별도의 Author 조회 쿼리가 발생하여 N+1 문제가 발생합니다.
반면, @DBRef(lazy = true)를 사용하면 Post를 조회할 때 Author 필드는 즉시 로딩되지 않고, 실제로 해당 필드에 접근하는 시점에서 별도의 쿼리가 실행됩니다. 이 방식은 초기 조회 시 불필요한 데이터를 로딩하지 않아 응답 속도가 빠를 수 있으나, Post 객체를 JSON으로 시리얼라이즈하거나 Author 필드에 접근하는 경우 예기치 못한 추가 쿼리가 발생할 위험이 있습니다.
결국, lazy = false와 lazy = true 설정 모두 각기 다른 방식으로 N+1 문제가 발생할 수 있는 잠재적인 한계를 지니므로, 상황에 따라 신중하게 선택하고 최적화 전략을 고려해야 합니다. 어떤 방식으로 쿼리가 발생하는지 살펴보겠습니다.
db.post.find({}).limit(500)
// post rows 만큼 반복
db.author.find({_id: ObjectId("67cd82c3aec68267745dcf85")}).limit(1)
db.author.find({_id: ObjectId("67cd82c3aec68267745dcf84")}).limit(1)
db.author.find({_id: ObjectId("67cd82c3aec68267745dcf83")}).limit(1)
// ...위 예시는 Post를 조회한 후, 별도의 쿼리로 Author 문서를 조회하는 과정을 보여줍니다. 만약 500개의 Post를 조회한다면, 각 Post마다 Author 조회 쿼리가 실행되어 총 500번의 db.author.find 쿼리가 발생하게 됩니다. 이처럼 Post 조회 결과의 수에 따라 반복적으로 Author 조회 쿼리가 실행되면 N+1 문제가 발생하여 성능 저하를 초래할 수 있습니다.
아래 코드는 Spring MVC 컨트롤러에서 Post 도큐먼트를 조회한 후, 두 가지 방식의 응답 처리를 비교하는 예시입니다. getPostWithAuthor 메서드는 전체 Post 객체를 리턴하여 JSON 시리얼라이즈 과정에서 Author 필드에 접근하게 됩니다. 반면, getPostOnly 메서드는 Projection 패턴을 활용하여 핵심 데이터만을 담은 PostProjection 객체를 리턴하므로, Author 필드에 접근하지 않아 추가 쿼리가 발생하지 않습니다.
@RestController
@RequestMapping("/posts")
class PostController(
private val postRepository: PostRepository,
) {
@GetMapping("/post-with-author")
fun getPostWithAuthor(@RequestParam(name = "limit") limit: Int): List<Post> = postRepository.find(limit)
@GetMapping("/post-only")
fun getPostOnly(@RequestParam(name = "limit") limit: Int): List<PostProjection> = postRepository.find(limit).map { PostProjection(it) }
}
data class PostProjection(
val id: ObjectId,
val title: String,
val content: String
) {
constructor(post: Post) : this(
id = post.id!!,
title = post.title,
content = post.content,
)
}
class PostCustomRepositoryImpl(mongoTemplate: MongoTemplate) : PostCustomRepository, MongoCustomRepositorySupport<Post>(
Post::class.java,
mongoTemplate
) {
override fun find(limit: Int): List<Post> {
return mongoTemplate.find(Query().limit(limit))
}
}-
getPostWithAuthor:
- 리턴 타입이
List<Post>이므로, Post 객체를 JSON으로 시리얼라이즈하는 과정에서 Author 필드에 접근하게 됩니다. - 이로 인해
lazy = false든lazy = true든 상관없이, 각 Post마다 별도의db.author.find쿼리가 실행되어 N+1 문제가 반복됩니다.
- 리턴 타입이
-
getPostOnly:
- 리턴 타입이
List<PostProjection>이므로, 응답에 필요한 핵심 데이터만 반환되고 Author 필드에 직접 접근하지 않습니다. - 따라서, lazy = true인 경우 추가적인 Author 조회 쿼리가 발생하지 않아 N+1 문제를 회피할 수 있습니다.
- 리턴 타입이
실제 동작이 어떻게 나가는지 본격적으로 살펴보겠습니다.
아래 이미지는 @DBRef(lazy = false)을 사용하여 Post를 조회할 때, 연관된 Author 문서까지 별도의 쿼리로 로딩되는 과정을 보여줍니다. 쿼리 로그에서 Post와 Author 각각에 대해 별도의 조회가 발생하는 것을 확인할 수 있으며, 여러 Post를 조회할 경우 N+1 문제가 명확하게 드러납니다.
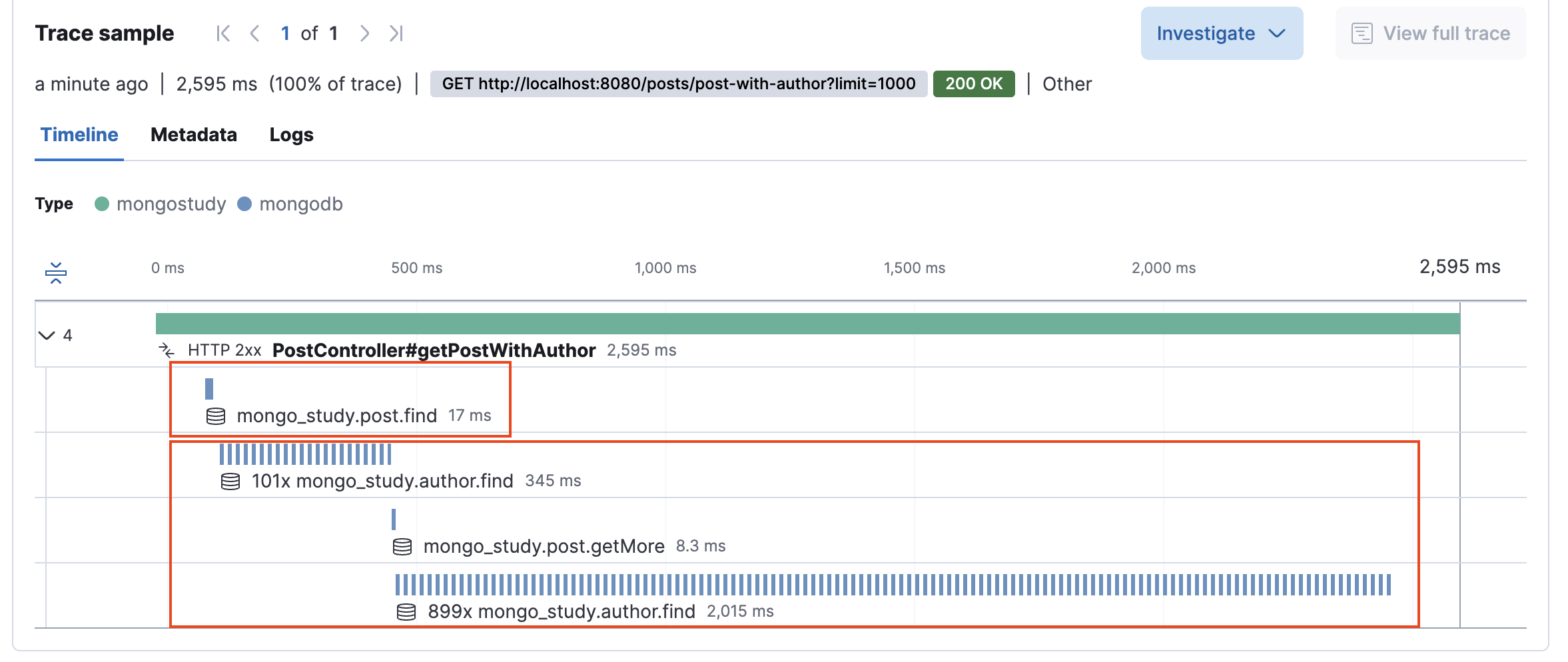
예를 들어, db.post.find({}).limit(1000) 쿼리는 약 17ms 정도 소요되지만, 각 Post마다 Author를 조회하는 db.author.find({_id: ObjectId("")}).limit(1) 쿼리가 1,000번 실행되어 총 2,361ms가 소요됩니다. 이 결과는 N+1 쿼리 문제로 인해 전체 조회 시간이 크게 늘어남을 명확하게 보여줍니다.
아래 이미지는 Post를 조회한 후 실제로 Author 필드에 접근할 때 별도의 Author 조회 쿼리가 실행되는 과정을 보여줍니다.
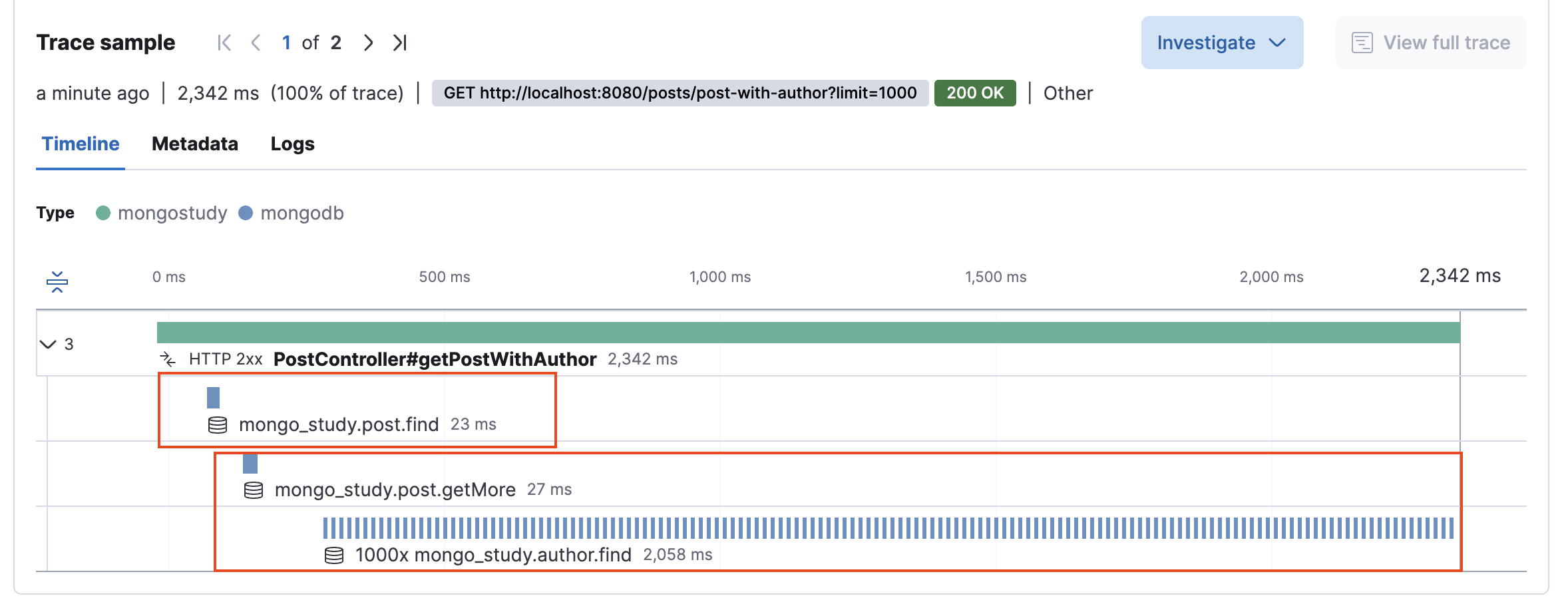
@DBRef(lazy = true)를 사용하더라도, Post 객체에서 Author 필드에 접근하면 추가 쿼리가 발생합니다. 예를 들어, db.post.find({}).limit(1000) 쿼리는 23ms 정도 소요되지만, 각 Post의 Author를 조회하는 쿼리 db.author.find({_id: ObjectId("")}).limit(1)가 1,000번 실행되어 총 2,085ms가 소요됩니다.
이처럼 실제 Author 필드에 접근하는 경우, @DBRef(lazy = false)와 유사한 성능 저하가 발생하게 됩니다.
반면, Post 조회 시 Author 필드에 전혀 접근하지 않으면 불필요한 Author 조회 쿼리가 발생하지 않아 응답 속도가 훨씬 빨라집니다.
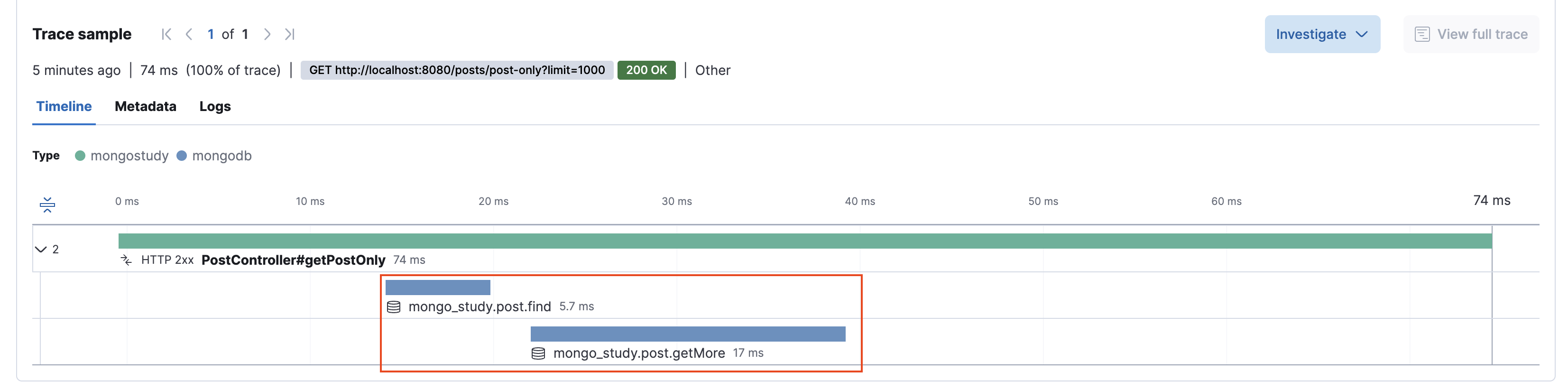
아래 이미지는 이러한 상황을 보여주며, db.post.find({}).limit(1000) 쿼리가 실행되어 약 22.7ms 정도 소요되었고, Author에 대한 접근이 없으므로 추가 쿼리가 발생하지 않은 것을 확인할 수 있습니다.
Kotlin에서는 클래스가 기본적으로 final로 선언되기 때문에, 특별한 설정 없이 작성된 클래스는 상속이 불가능합니다. Proxy 기반의 Lazy 로딩은 실제 객체 대신 프록시 객체를 생성하여 해당 객체의 속성에 접근할 때 실제 데이터를 로딩하는 방식으로 동작합니다. 이를 위해서는 대상 클래스가 open이어야 하는데, 만약 클래스가 final이면 프록시 객체를 생성할 수 없으므로 Lazy 로딩이 제대로 동작하지 않습니다.
예를 들어, Author 클래스가 final 상태라면 Spring Data MongoDB는 CGLIB를 사용해 해당 클래스를 상속하는 프록시 객체를 생성하려 할 때 다음과 같은 오류가 발생합니다.
java.lang.IllegalArgumentException: Cannot subclass final class com.example.mongostudy.dbref.Author
at org.springframework.cglib.proxy.Enhancer.generateClass(Enhancer.java:660)
...
이를 해결하기 위해 Kotlin에서는 all-open 플러그인 또는 kotlin-spring 플러그인을 적용하여, 특정 애노테이션(예: @Document)이 붙은 클래스를 자동으로 open으로 변환할 수 있습니다. 아래 예시는 이러한 설정을 적용하는 방법을 보여줍니다.
plugins {
id("org.jetbrains.kotlin.plugin.spring") version "1.6.21"
// 또는 id("org.jetbrains.kotlin.plugin.allopen") ...
}
allOpen {
annotation("org.springframework.data.mongodb.core.mapping.Document")
}이 설정을 적용하면, @Document 애노테이션이 붙은 클래스들은 자동으로 open으로 처리되어 프록시 객체 생성이 가능해집니다. 즉, Lazy 로딩이 원활하게 동작할 수 있습니다.
아래 이미지는 Lazy 로딩이 활성화된 상태에서 Author 필드를 지연 로딩하기 위해 생성된 LazyLoadingProxy 객체를 보여줍니다. 이 프록시 객체는 실제 Author 데이터에 접근할 때 필요한 시점에 데이터를 로딩하도록 구성되어 있습니다.
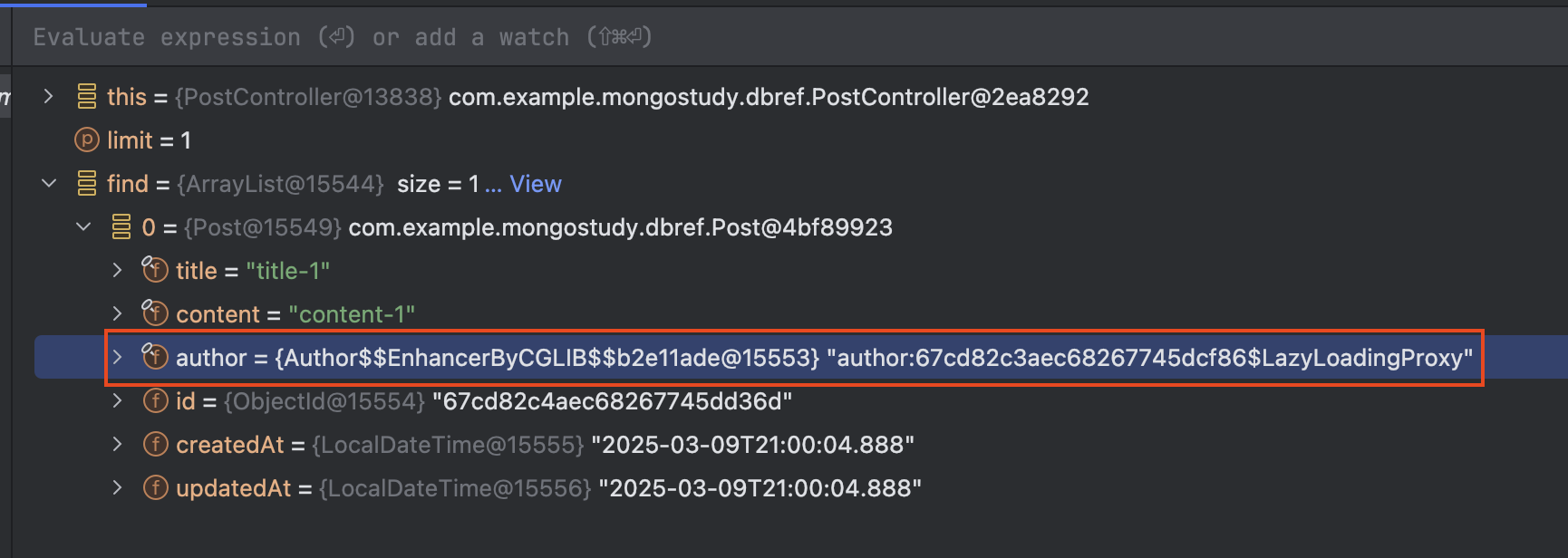
결국, 도메인 클래스가 open 상태로 변환되지 않으면 프록시 객체 생성이 불가능하여 Lazy 로딩이 실패하게 됩니다. 따라서, Spring Data MongoDB에서 Lazy 로딩 기능을 활용하려면 반드시 위와 같은 설정을 통해 대상 도메인 클래스가 open 상태로 유지되도록 해야 합니다.
위 조회에서 살펴보았듯이, @DBRef 기반으로 연관 객체를 포함하여 조회하면 N+1 문제가 발생할 수밖에 없습니다. 이를 해결하기 위해 MongoDB의 $lookup 연산자를 활용할 수 있습니다.
$lookup은 MongoDB의 Aggregation Pipeline에서 제공되는 연산자로, 두 컬렉션을 조인(join)하는 역할을 합니다. 이는 RDBMS의 Join과 유사하게 동작하여, 한 컬렉션의 데이터를 기준으로 관련된 다른 컬렉션의 데이터를 한 번의 Aggregation 쿼리로 가져올 수 있습니다. 이렇게 하면 각 Post마다 별도의 Author 조회 쿼리가 발생하는 N+1 문제를 효과적으로 해결할 수 있습니다.
db.post.aggregate(
[
{
"$lookup": {
"from": "author",
"localField": "author.$id",
"foreignField": "_id",
"as": "author"
}
},
{
"$unwind": {
"path": "$author",
"preserveNullAndEmptyArrays": true
}
},
{
"$project": {
"title": 1.0,
"content": 1.0,
"author": 1.0
}
},
{
"$limit": 500.0
}
]
)이 예제는 $lookup 연산자를 사용하여 Post와 Author 컬렉션을 조인하는 방법을 보여줍니다.
$lookup은 MongoDB의 Aggregation Pipeline 단계 중 하나로, 한 컬렉션의 필드를 기준으로 다른 컬렉션의 관련 데이터를 조인하여 한 번의 쿼리로 가져올 수 있습니다. 이를 통해 단일 Aggregation 파이프라인으로 모든 연관 데이터를 한 번에 조회할 수 있어, 각 Post마다 별도의 Author 조회 쿼리가 발생하는 N+1 문제를 효과적으로 회피할 수 있습니다.
아래 코드는 Spring MVC 컨트롤러에서 $lookup을 사용하여 Post와 Author 데이터를 한 번의 Aggregation 쿼리로 조회하는 예시입니다. 이 방식은 기존의 @DBRef 방식을 사용하여 발생하는 N+1 문제를 효과적으로 회피합니다.
@RestController
@RequestMapping("/posts")
class PostController(
private val postRepository: PostRepository,
) {
@GetMapping("/lookup")
fun getPostsLookUp(@RequestParam(name = "limit") limit: Int): List<Post> = postRepository.findLookUp(limit)
}
data class PostProjectionLookup(
val id: ObjectId,
val title: String,
val content: String,
val author: AuthorProjection
)
interface PostCustomRepository {
fun findLookUp(limit: Int): List<PostProjectionLookup>
}
class PostCustomRepositoryImpl(mongoTemplate: MongoTemplate) : PostCustomRepository, MongoCustomRepositorySupport<Post>(
Post::class.java,
mongoTemplate
) {
override fun findLookUp(limit: Int): List<PostProjectionLookup> {
val lookupStage = Aggregation.lookup(
"author", // from: 실제 컬렉션 이름
"author.$id", // localField: DBRef에서 _id가 들어있는 위치
"_id", // foreignField: authors 컬렉션의 _id
"author" // as: 결과를 저장할 필드 이름
)
val unwindStage = Aggregation.unwind("author", true)
val projection = Aggregation.project()
.andInclude("title")
.andInclude("content")
.andInclude("author")
val limitStage = Aggregation.limit(limit.toLong())
val aggregation = Aggregation.newAggregation(lookupStage, unwindStage, projection, limitStage)
return mongoTemplate
.aggregate(
aggregation,
"post",
PostProjectionLookup::class.java,
)
.mappedResults
}
}getPostsLookUp 메서드는 단일 Aggregation 쿼리를 통해 Post와 Author 데이터를 한 번에 조회합니다. 이 과정에서 $lookup 연산자가 두 컬렉션 간의 조인을 수행하고, $unwind를 사용해 조인된 Author 데이터를 평탄화합니다. 결과적으로 모든 연관 데이터를 한 번에 가져오기 때문에 각 Post마다 별도의 Author 조회 쿼리가 실행되는 N+1 문제가 발생하지 않으며, 대량의 데이터를 조회하는 상황에서도 성능 저하를 효과적으로 방지할 수 있습니다.
또한, 아래와 같이 단순히 author_id만을 저장하는 방식으로 도메인 모델을 구성한 경우에도, $lookup을 통해 연관 Author 데이터를 조회할 수 있습니다. 이는 반드시 @DBRef로 연관관계를 매핑할 필요 없이, 단순 ID 저장 방식만으로도 연관 데이터를 조인할 수 있음을 보여줍니다.
@Document(collection = "post")
class Post(
@Id
var id: ObjectId? = null,
@Field(name = "title", targetType = FieldType.STRING)
val title: String,
@Field(name = "content", targetType = FieldType.STRING)
val content: String,
@Field(name = "author_id")
val authorId: ObjectId
)이와 같이 $lookup 기반의 조회 방식은 연관 문서 매핑 없이도 단일 Aggregation 쿼리로 Post와 Author 데이터를 한 번에 가져올 수 있으므로, N+1 문제를 근본적으로 해결할 수 있는 효과적인 대안임을 강조할 수 있습니다.
실제 동작이 어떻게 나가는지 본격적으로 살펴보겠습니다.
아래 이미지는 $lookup 방식을 사용하여 Post와 Author 데이터를 단일 Aggregation 쿼리로 조회한 결과를 보여줍니다. 쿼리 로그를 통해 두 컬렉션 간의 조인과 함께 Author 데이터가 평탄화되어 처리되는 과정을 확인할 수 있으며, 이 방식은 모든 연관 데이터를 한 번에 가져와 N+1 문제를 효과적으로 회피함을 증명합니다.
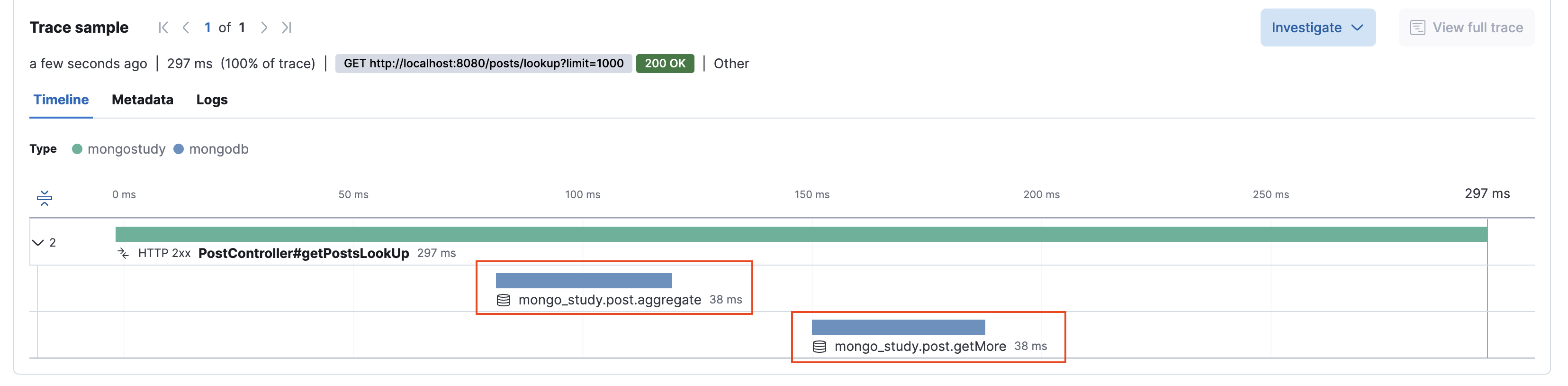
또한, Post와 Author 데이터를 한 번에 조회하는 db.post.aggregate 쿼리가 약 76ms 만에 완료된 것을 확인할 수 있으며, 이를 통해 성능이 매우 빨라졌음을 확인할 수 있습니다.
아래 이미지는 각 조건을 10회씩 테스트한 후 산출된 평균 응답 시간을 비교한 벤치마크 결과를 보여줍니다.
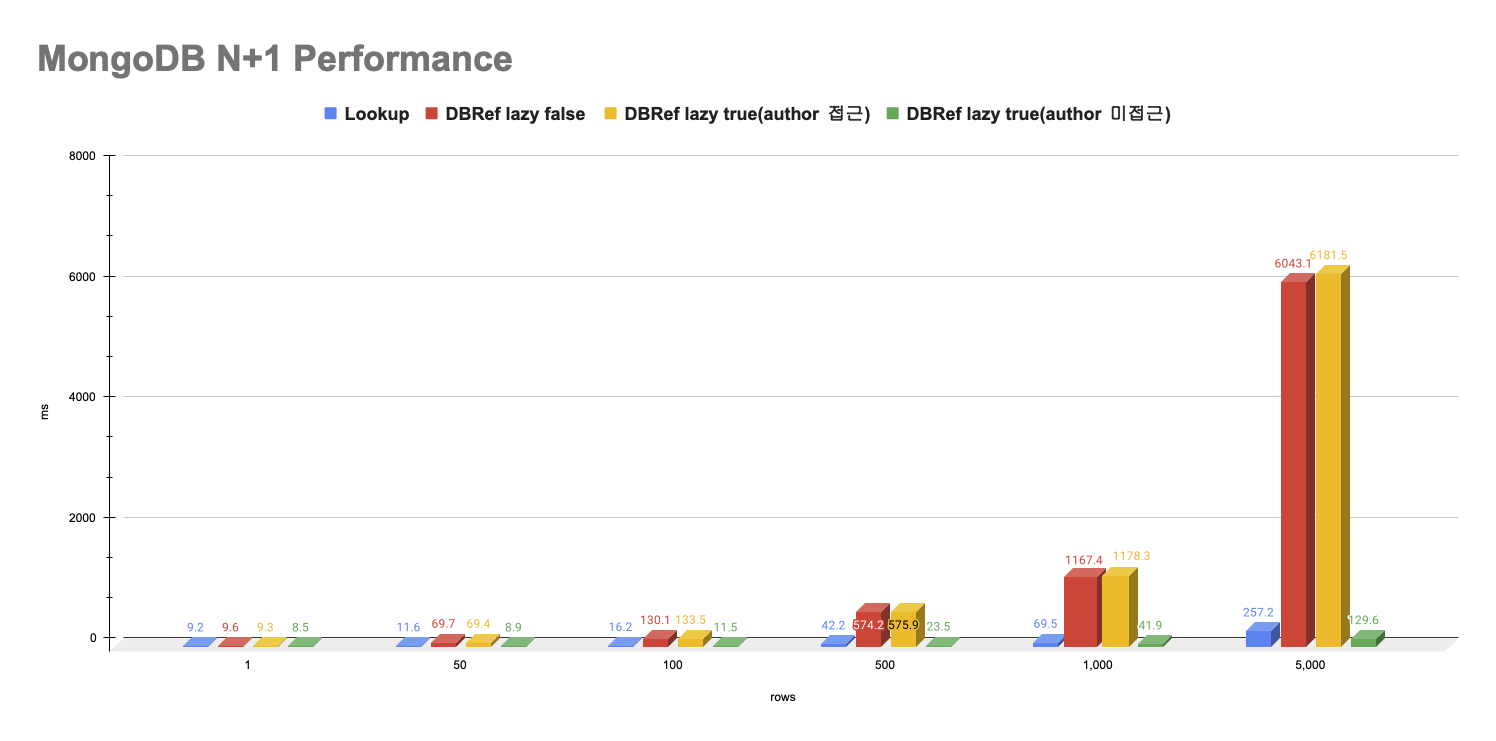
| rows | $lookup | DBRef lazy false | DBRef lazy true(author 접근) | DBRef lazy true(author 미접근) |
|---|---|---|---|---|
| 1 | 9.2ms | 9.6ms | 9.3ms | 8.5ms |
| 50 | 11.6ms | 69.7ms | 69.4ms | 8.9ms |
| 100 | 16.2ms | 130.1ms | 133.5ms | 11.5ms |
| 500 | 42.2ms | 574.2ms | 575.9ms | 23.5ms |
| 1,000 | 69.5ms | 1167.4ms | 1178.3ms | 41.9ms |
| 5,000 | 257.2ms | 6043.1ms | 6181.5ms | 129.6ms |
테스트 결과를 요약하면, 단일 문서 조회에서는 모든 방식이 거의 동일한 응답 속도를 보입니다. 그러나 조회 대상 문서 수가 증가할수록 각 방식 간의 성능 차이가 뚜렷하게 나타납니다.
특히, Author 필드에 접근하는 경우, lazy 설정이 true든 false든 상관없이 각 Post마다 추가 쿼리가 실행되어 N+1 문제가 발생합니다. 이로 인해, 예를 들어 1,000건의 Post를 조회하면 약 1,000ms 정도의 응답 속도가 소요되어, 실제 서비스에 적용하기에는 다소 부적합 수 있습니다.
반면, lazy=true 설정에서 Author 필드에 접근하지 않는 경우에는 단순 find 쿼리만 실행되므로 가장 빠른 응답 속도를 기록합니다. 만약 Author 정보에 접근해야 하는 상황이라면, $lookup 연산자를 활용해 db.post.aggregate 쿼리를 통해 Post와 Author 데이터를 한 번에 조회함으로써 N+1 문제를 효과적으로 회피할 수 있습니다. 이러한 방식은 Author 접근이 필요한 경우에 가장 효율적인 대안으로 평가됩니다.
기존 구현에서는 Lookup 결과의 리턴 타입을 PostProjectionLookup과 같이 별도의 Projection 객체로 지정했습니다. 그러나 이 방식은 Post 도큐먼트 내에 정의된 비즈니스 로직(DDD 관점에서 핵심 도메인 기능)을 그대로 활용할 수 없다는 단점이 있습니다. 즉, Post 객체가 갖는 도메인 메서드를 이용하여 비즈니스 규칙을 적용할 수 없게 되어, 객체지향 설계 원칙에 위배되는 문제가 발생합니다.
또한, 상속을 통해 메서드를 재사용하는 방법은 재사용을 위해 인위적으로 상속 관계를 도입하는 방식이므로, 이는 최적의 해결책이라고 보기 어렵습니다. 이러한 문제를 해결하기 위해 가장 좋은 방법은 Aggregation 쿼리의 결과를 바로 Post 객체로 리턴하는 것입니다. 이렇게 하면 Post 도큐먼트에 정의된 비즈니스 로직을 그대로 유지하면서도, $lookup 방식의 장점을 활용하여 N+1 문제를 회피할 수 있습니다.
class PostCustomRepositoryImpl(mongoTemplate: MongoTemplate) : PostCustomRepository, MongoCustomRepositorySupport<Post>(
Post::class.java,
mongoTemplate
) {
override fun findLookUp(limit: Int): List<Post> {
// ...
val aggregation = Aggregation.newAggregation(lookupStage, unwindStage, projection, limitStage)
return mongoTemplate
.aggregate(
aggregation,
"post",
Post::class.java // 리턴 타입을 Post 객체로 지정
)
.mappedResults
}
}이와 같이 구현하면, Post 객체에 내장된 도메인 로직을 그대로 활용할 수 있으며, 불필요한 상속 관계를 도입하지 않고도 $lookup 방식을 통해 연관 데이터를 한 번에 조회할 수 있습니다.
중요한 것은 포인트는 Post 클래스 내에서 author 필드를 다음과 같이 lazy로 설정하는 점입니다.
@Document(collection = "post")
class Post(
// ...
@DBRef(lazy = true)
val author: Author,
)이렇게 하면, 일반적인 find 조회에서는 author 필드에 접근하기 전까지 추가 쿼리가 발생하지 않아 N+1 문제를 어느 정도 회피할 수 있고, 필요할 때는 $lookup을 통해 author 정보도 함께 조회할 수 있습니다.
단, lazy로 설정되어 있기 때문에 find 쿼리 이후 author 객체에 접근하면 추가적인 N+1 문제가 발생할 수 있으므로, 이 방식은 N+1 문제를 완전히 해결하는 것은 아니며 잠재적인 문제가 남아 있음을 유념해야 합니다. 이러한 잠재적 문제를 근본적으로 해결하려면, 객체 간의 연관관계를 맺지 않고 단순한 값 객체인 author_id를 보유하는 모델링 방식을 고려해야 합니다.
예를 들어, 아래와 같이 Post 도큐먼트를 구성할 수 있습니다.
@Document(collection = "post")
class Post(
// ...
@Field(name = "author_id")
val authorId: ObjectId
)이 경우, N+1 문제를 원천적으로 해결하기 위해 Post는 단순한 값 객체인 author_id만을 저장하고, Author 객체에 접근이 필요한 경우에는 $lookup을 통해 두 컬렉션을 조인하여 데이터를 가져올 수 있습니다.
또한, 객체 간 연관관계를 단순히 성능 문제만으로 판단하기보다는, DDD에서 제시하는 에그리거트 경계를 기준으로 도메인 모델을 구성하는 것도 고려해볼 만한 합리적인 접근 방식입니다. 이를 통해 도메인 로직과 성능 최적화를 균형 있게 반영할 수 있습니다.
만약 @DBRef(lazy = true)로 연관관계를 설정하는 것을 선택한다면, MongoRepository에서 제공해주는 기본 메서드들을 override하여 $lookup을 활용해 한 번에 조회하는 방법을 적용할 수도 있습니다. 예를 들어, findByIdOrNull 메서드를 사용하면 Lazy 로딩 시 Author 데이터에 접근할 때 N+1 문제가 발생할 수 있으므로, 이를 $lookup 기반으로 재정의하여 한 번의 Aggregation 쿼리로 데이터를 조회하도록 구현하는 것도 좋은 선택입니다.
class PostCustomRepositoryImpl(mongoTemplate: MongoTemplate) : PostCustomRepository, MongoCustomRepositorySupport<Post>(
Post::class.java,
mongoTemplate
) {
override fun findByIdOrNull(id: ObjectId): Post? {
val match = Aggregation.match(Criteria.where("_id").`is`(id))
val lookupStage = Aggregation.lookup(...)
val unwindStage = Aggregation.unwind("author", true)
val projection = Aggregation.project(...)
val aggregation = Aggregation.newAggregation(match, lookupStage, unwindStage, projection)
return mongoTemplate
.aggregate(
aggregation,
"post",
Post::class.java,
)
.uniqueMappedResult
}
}이와 같이 구현하면, @DBRef(lazy = true)를 사용하는 경우에도 기본 메서드를 $lookup 기반으로 재정의하여 한 번의 Aggregation 쿼리로 연관 데이터를 조회할 수 있습니다. 이를 통해 N+1 문제를 효과적으로 회피할 수 있습니다.
이번 글에서는 Spring Data MongoDB에서 @DBRef를 활용한 객체 간의 연관관계 설정, 이로 인한 N+1 문제, 그리고 이를 해결하기 위한 다양한 최적화 전략을 살펴보았습니다.
핵심 요약은 다음과 같습니다.
- @DBRef 방식의 한계:
@DBRef를 사용하면 연관 문서를 로딩할 수 있지만, Post를 조회할 때마다 별도의 Author 조회 쿼리가 발생하여 N+1 문제가 발생할 위험이 있습니다. - Lazy 옵션의 한계:
@DBRef(lazy = true)를 적용해도, 실제 Author 데이터에 접근하는 시점에서는 추가 쿼리가 실행되므로 N+1 문제를 완전히 회피하기는 어렵습니다. - 효과적인 대안:
MongoDB의$lookup연산자를 활용해 단일 Aggregation 쿼리로 Post와 Author 데이터를 한 번에 조회하면, 각 Post마다 별도의 조회 쿼리가 실행되는 N+1 문제를 효과적으로 회피할 수 있습니다. - 모델링 접근 방식:
Post 도큐먼트에서 연관 객체를@DBRef대신 단순 값 객체인author_id로 보유하거나, 기본 Repository 메서드를$lookup기반으로 재정의하는 방법도 고려할 수 있습니다. - DDD 관점:
객체 간 연관관계를 단순 성능 문제만으로 판단하지 않고, DDD에서 제시하는 에그리거트 경계를 기준으로 도메인 모델을 구성하는 접근도 함께 고려하여, 도메인 로직과 성능 최적화를 균형 있게 반영할 수 있습니다.
이와 같이 다양한 전략을 상황에 맞게 조합하면, N+1 문제를 최소화하면서도 도메인 로직을 효과적으로 유지할 수 있는 유연한 설계가 가능함을 확인할 수 있습니다.