SQL로 검색 쿼리를 구현한다고 하면, 읿잔적으로 LIKE문으로 검색한다. 많은 양의 데이터가 있는 테이블도 아니고, 검색도 빈번하게 발생하는 게 아니라면 별 문제 없이 검색 기능을 구현할 수 있지만 데이터가 100만건, 1000만건 억 단위로 늘어나게 된다면 문제가 될 수 있다.
왜 문제가 될 수 있는 것일까? LIKE문의 문제점을 한 번 알아보도록 하자.
아래 예시에서 table A에 title이라는 컬럼에 인덱스가 걸려있다고 가정해보겠다.
SELECT * FROM table_A WHERE title LIKE 'something%';SELECT * FROM table_A WHERE title LIKE '%something';SELECT * FROM table_A WHERE title LIKE '%something%';위에처럼 like문은 특정 문자열 포함 여부에 따라서 총 세 가지의 형태로 구분할 수 있다.
여기서 중요한 점은 데이터의 앞부분에 문자열이 포함되는지 체크하는 경우에만 인덱스를 타게 된다는 점이다.
즉 아래 두 쿼리는 인덱스를 탈 수 없다는 것이다. (full scan으로 데이터 조회)
SELECT * FROM table_A WHERE title LIKE '%something';SELECT * FROM table_A WHERE title LIKE '%something%';왜 그럴까? 이는 Index 자료구조의 특징때문에 한계가 있는 것이다.
MySQL(InnoDB)에서는 인덱스가 B+Tree 자료구조로 관리가 된다.
B+Tree는 기본적으로 데이터를 정렬된 형태로 들고 있기 때문에 특정 문자열로 시작하는 데이터는 인덱스 스캔을 통해서 주소값을 알아낼 수 있지만, 그렇지 않은 값들은 모든 테이블을 뒤져야만 만족하는 데이터를 찾을 수 있는 것이다.
SELECT * FROM table_A WHERE title LIKE '%something%';보통 위와같은 방식으로 우리는 검색 쿼리를 작성하는데, 이렇게 되면 테이블 풀스캔을 통해서 조건에 맞는 데이터를 찾는 수 밖에 없게 된다. 그렇기 때문에 데이터의 양이 매우 많은 테이블에 대해서는 검색 기능을 제공하려면 Full-text search 기능을 활용하는 것이 좋다.
Full Text Index는 MySQL InndoDB or MyISAM 엔진에서만 사용할 수 있고, char, varchar, text 같은 타입 컬럼에만 적용할 수 있다.
Full text search를 활용하기 위해선 해당 기능을 사용하고자 하는 컬럼에 full-text index를 먼저 설정해줘야한다.
Full-text Index 생성
CREATE FULLTEXT INDEX {INDEX_NAME} ON {TABLE_NAME} ({COLUMN}); -- built in parser 사용or
CREATE FULLTEXT INDEX {인덱스 이름} ON {테이블} ({컬럼}) WITH PARSER ngram; -- ngram parser 사용여기서 Built in Parser는 기본적으로 공백을 기준으로 단어를 구분해서 파싱하고 Ngram Parser는 하나의 문장을 최소 토큰 수 만큼 모두 나눠서 기록한다는 특징이 있다.
예를 들어서 "안녕하세요 반갑습니다" 라는 문장이 있다면 Built in Parser는 '안녕하세요', '반갑습니다'로 파싱해서 인덱스를 생성한다.
반면 ngram parser는 '안녕' '하세' '요반' '반갑' '습니' '니다'와 같은 형식으로 파싱한다. 각자 상황에 따라서 어떤 파서를 사용할지 선택하는 것이 좋다.
Full-text Index 제거 방법
DROP INDEXT {인덱스 이름} on {테이블} ;인덱스 조회
SHOW INDEX FROM {테이블};위에서 생성한 샘플 테이블에 Full-Text index를 생성하고, 어떻게 index 데이터가 이루어지는지 확인해보자.
SET GLOBAL innodb_ft_aux_table = 'index_test/book'; # {db명/table명}
SELECT * FROM information_schema.innodb_ft_index_table;위에 쿼리를 수행하면 어떻게 Full-Text Index가 걸려있는지 확인할 수 있다.

위 그림처럼 InnoDB에서 Full-text Indexing에 대상이 되는 글자 수는 3글자 이상이여서 3글자 이상으로 구성된 어절들만 인덱싱이 된 것을 확인할 수 있다.
Full-Text Index가 걸릴 최소 글자 수 조건은 3글자로 되어있지만 이를 또 수정할 수 있다.
InnoDB 에서는 innodb_ft_min_token_size가 최소 인덱싱 글자 수를 의미하고, 그 외의 엔진에서는 ft_min_word_len 이 그 역할을 한다. 그리고, built-in parser가 아니라 ngram parser를 쓸 때는 ngram_token_size를 통해서 최소 토큰 크기(인덱싱된 글자의 크기)를 사용한다.
SHOW VARIABLES LIKE 'innodb_ft_min_token_size';위 쿼리를 수행하면, 몇 글자부터 indexing 대상이 되는지 확인할 수 있다.
이제 아래 방법에 따라서 이 설정 값을 수정해보겠다.
conf 파일로 위치를 이동해서
cd /etc/mysql/mysql.conf.dmysqld.conf에 설정 값을 수정하거나 혹은 추가한다.
vim mysqld.confinnodb_ft_min_token_size = 2
이후 서버를 재실행하면 설정이 적용된 것을 확인할 수 있다.
service mysql restart이제 다시 Full-Text Index를 DROP한 후 재생성을 해보자. 그러면, 아래와 같이 두 글자의 텍스트부터 Full-Text-Index가 설정된 것을 확인할 수 있다.
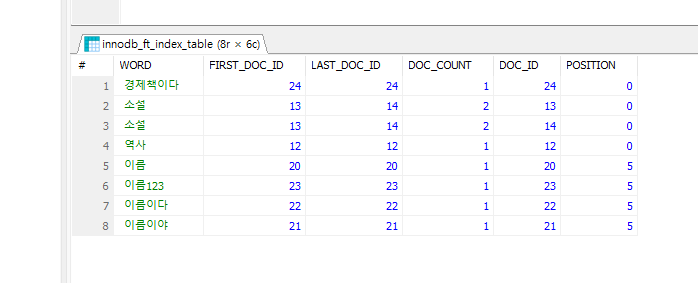
innodb_ft_min_token_size의 값과 Parser의 종류에 따라서 Full-text index 되는 방식이 매우 달라지고, 그에 따라서 아래에서 소개할 Full-Text search의 결과들 또한 많이 달라지게 된다. 내가 필요한 방식이 어떤 것인지 잘 파악하고 설정 값과 Parser를 잘 설정해야한다