이번 글에서는 파티셔닝의 두가지 종류와 분할 기준에 대해서 한 번 알아보도록 하겠다.
파티셔닝은 다음과 같은 두 종류로 나누어져있다.
- 수평 파티셔닝
- 수직 파티셔닝
하나씩 알아보도록 하자.
수평 파티셔닝은 row를 기준으로 테이블을 분할 시키는 것으로 샤딩과 메커니즘이 같다.
샤딩과의 차이점은 분할된 테이블을 하나의 DB에 저장시키냐 여러 DB에 저장시키냐의 차이다.
분할 시키는 기준은 한 데이터에 대한 기준으로 파티셔닝 키라고도 한다.
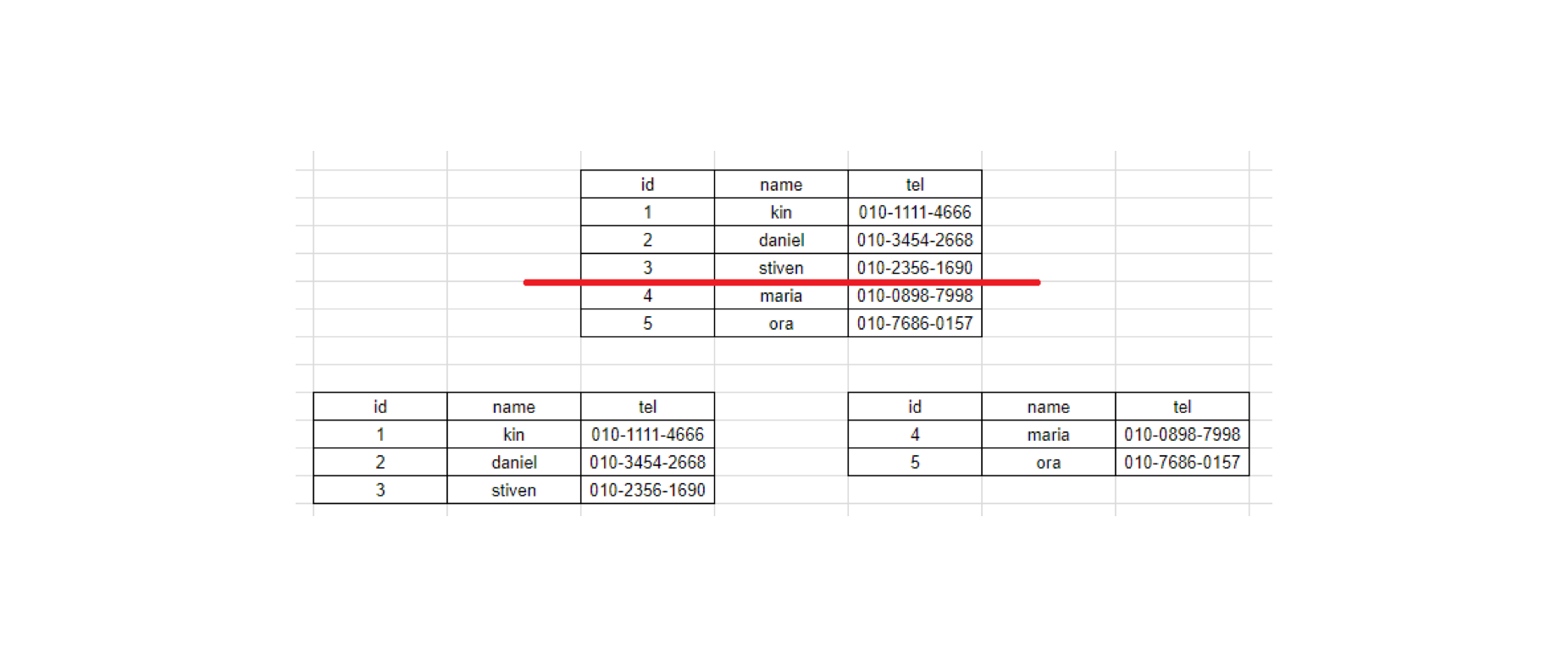
파티셔닝 키를 기준으로 테이블을 분할하고 저장해서 관리한다.
퍼포먼스와 가용성을 위해 파티셔닝 키 기반으로 분할해서 관리하는 것이다.
예시로 고객 아이디를 1~10000까지는 테이블 A 10001 ~ 20000 까지는 B에 저장한다고 해보자.
이것을 고객 아이디를 파티셔닝 키로해 수평 파티셔닝을 한 것이다. (range 분할)
여기서 파티셔닝 키를 분할하는 기준이 있는데, 아래에서 한 번 더 언급하도록 하겠다.
수평과 다르게 column을 기준으로 테이블을 분할하는 것이다.
3정규화랑 비슷한 개념이기도 하다.
하나의 엔티티를 2개로 분리하는 작업이기도 하며, 수평과 다르게 같은 스키마의 테이블을 나누는 것이 아닌 스키마를 나누고 데이터가 따라 옮겨간다.
3정규화랑 비슷하다고 생각할 수 있지만 3정규화랑은 다르게 이미 정규화된 테이블을 분할하는 것이니 조금 다르다.
장점으로는 자주 사용되는 컬럼, 용량이 많이 드는 데이터타입의 컬럼등을 분리해 I/O 성능을 높일 수 있다.
여기서 예시를 들어보자면 board라는 테이블에 content title writer_id 와 같은 정보가 있을때 title, writer_id만 가져오려고 DB에서 I/O 작업을 처리한다면, select 문으로 특정 컬럼을 지정했을때도 content까지 함께 메모리로 읽어 그곳에서 필터링을 거친다. 그렇기 때문에 content같은 용량이 높을 수 있는 컬럼을 항상 같이 가져온다는 것은 테스크 레이턴시를 올려버릴 수 있다.
위와 같은 이유로 자주 사용되는, 사용되지 않는 컬럼을 분리함으로써 입출력의 성능을 향상시킬 수 있다.
DBMS는 테이블을 분할할 때 각종 분할 기법들을 제공하고있다. 이때 파티셔닝 키가 함께 사용된다.
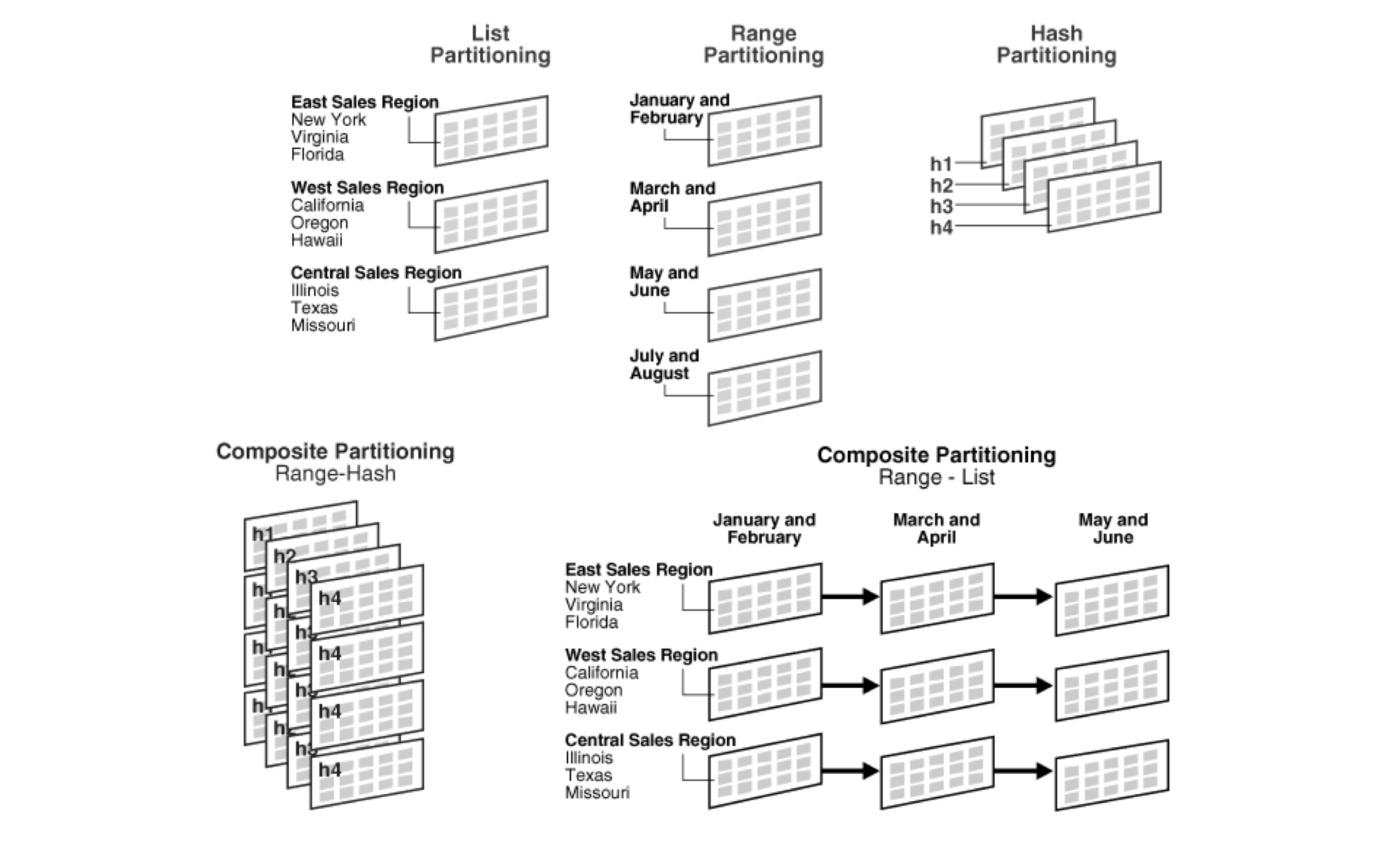
위와 같이 네 개의 파티셔닝 분할 기법이 있는데 하나씩 알아보자
분할 키 값의 범위를 기준으로 키를 구분한다.
예를 들면 우편번호로 1~10000 번 사이의 번호 이런식으로 범위를 나누는 것이다.
값 목록에 파티션을 힐당하고 파티션 키 값을 그 해당 목록에 해당하는지 확인하여 파티션을 선택한다.
예를 들면 Country라는 column안에 Japan, Korea, China가 들어있다면 아시아 국가의 파티션을 구축할 수 있는 것이다.
해시 함수의 값에 따라서 파티션 키를 분할하는 것이다.
4개의 파티션 테이블이 있다면 이 해시 함수는 0 ~ 3까지의 값을 반환한다.
위의 3개의 분할 기법들을 조합해서 사용하는 것을 의미한다.
예를 들어 먼저 범위를 분할한 후 해시 분할을 하는 것으로 생각할 수 있다.
컨시스턴트 해시법은 해시 분할 및 목록 분할의 합성으로 간주 될 수 있고 키 공간을 해시 축소함으로써 일람할 수 있게 한다.