- 데이터모델링을 할 때 정규화를 정확하게 수행한다.
- 데이터베이스 용량 산정을 수행한다.
- 데이터베이스에 발생되는 트랜잭션의 유형을 파악한다.
- 용량과 트랜잭션의 유형에 따라 반정규화를 수행한다.
- 이력 모델의 조정, PK,FK 조정, 슈퍼타입, 서브타입 조정 등을 수행한다.
- 성능관점에서 데이터모델을 검증한다.
정규화의 기본 목표는 테이블 간에 중복된 데이터를 허용하지 않는다는 것이다.
중복된 데이터를 허용하지 않음으로써 무결성(Integrity)를 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있다.
이러한 테이블을 분해하는 정규화 단계가 정의되어 있는데, 여기서 테이블을 어떻게 분해되는지에 따라 정규화 단계가 달라진다.
- 중복을 제거하여 공간 절약
- 데이터 무결성 보장, 정확성과 일관성을 유지
- 삽입, 삭제, 갱신 이상의 발생 가능성을 줄인다.
- 데이터 조회 시 조인의 수가 증가
- 업무가 변경되도 모델의 유연성을 향상
- 엔터티 의미 해석이 명확해진다.
- 테이블의 수가 증가
- 모델의 독립성을 향상시킴
제1 정규화 ~ 제5 정규화 실제로는 3 정규화 까지만 시행한다.
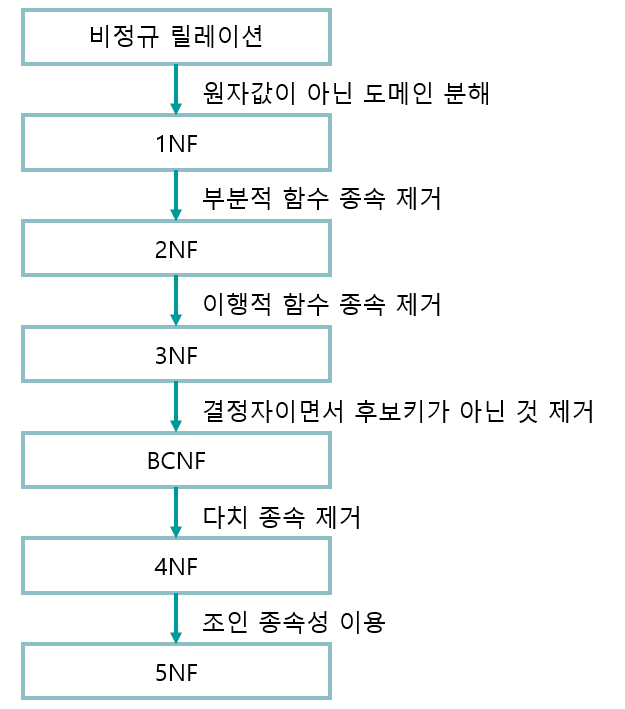
- 모든 속성이 원자값만으로 되어있는 형태
- M : N 관게를 1: M 관계로 변환
- 모든 속성은 반드시 기본키에 완전 함수적 종속을 만족 한다.
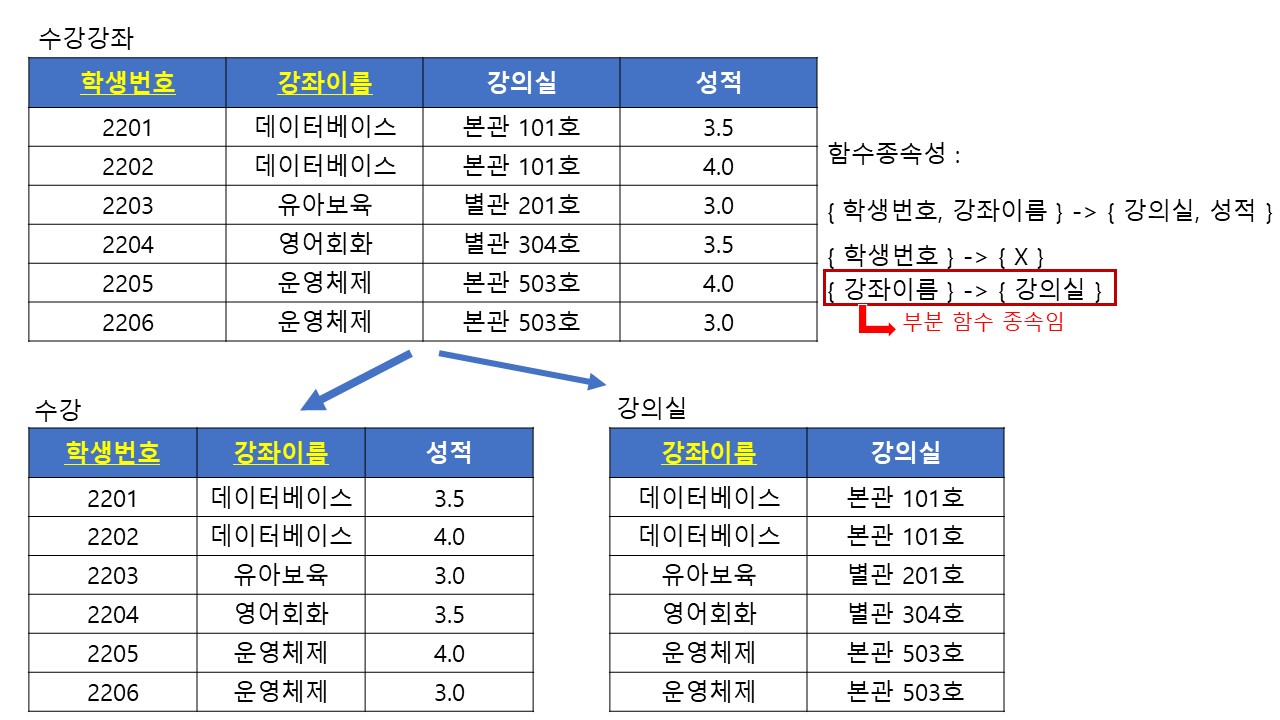
- 부분적 함수 종속성을 제거한다
- but, 제 1 정규화 결과 기본키가 하나라면 생략한다.
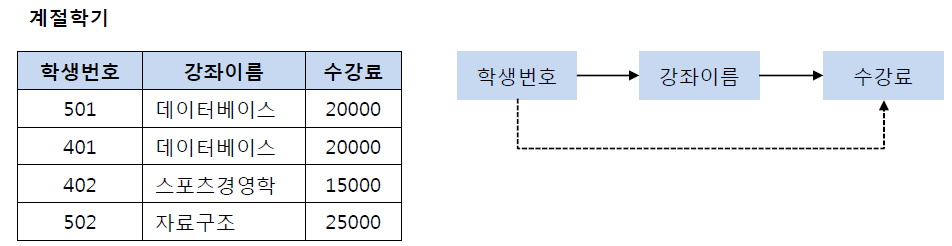
- 이행함수 종속성 제거
- 이행적 종속? : A -> B, B -> C 이면 A -> C가 성립되는 것을 의미
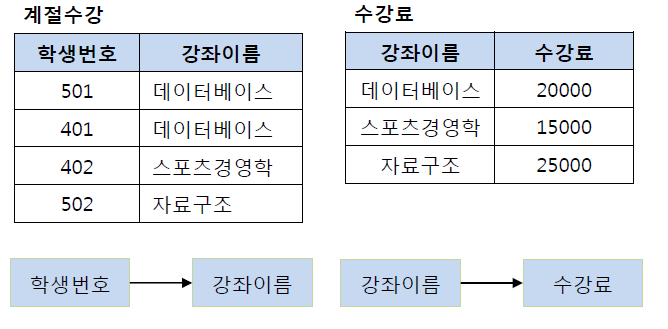
제 3 정규화를 거치게 된다면 다음과 같아진다.
- 모든 결정자가 후보키인 정규형
- 제 3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분리시키는 것
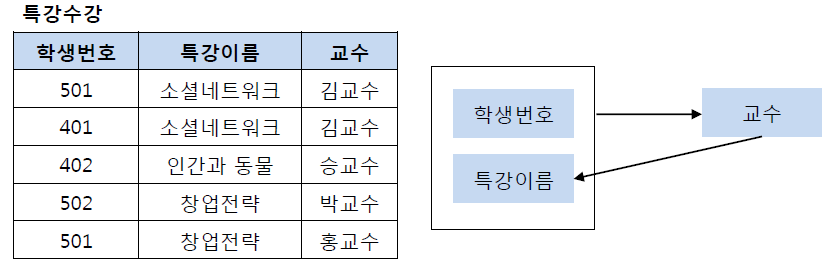
이 테이블에서 기본키는 학생번호, 특강 이름이다.
- 기본키는 교수를 결정하고 있다.
- 교수는 특강 이름을 결정하고 있다.
문제는 교수가 특강 이름을 결정하는 결정자 이지만, 후보키가 아니라는 점이다.
그렇기에 특강 신청 테이블 학생번호, 교수와 특강 교수 테이블 특강이름, 교수로 분리하여 BCNF 정규형을 만족시킬 수 있다.
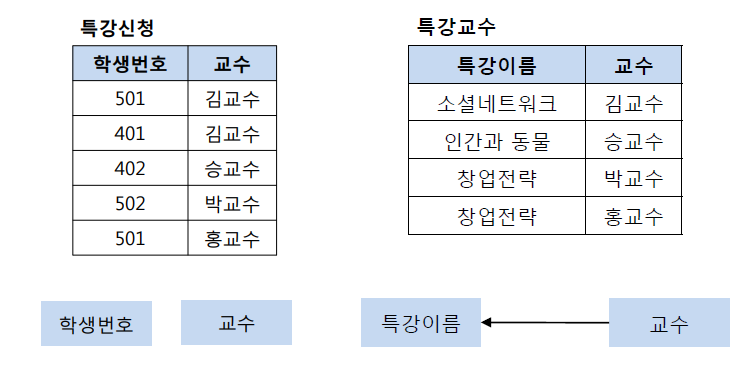
- 다중 값 종속성 제거
- 조인 종속성 제거